Abschnitt I - Theoretische Grundlagen
1
Einleitung
Die vorliegende Arbeit umfasst grundsätzliche Betrachtungen sowie eine Implementierung von informationstechnischer Unterstützung des sportwissenschaftlich basierten Trainingsplanungsprozesses.
Im ersten Abschnitt werden die sportwissenschaftlichen Grundlagen erarbeitet und in dieser Arbeit untersuchte Einsatzgebiete der Informatik abgegrenzt. Dabei wird auf die Praxis der Trainingsplanung, Leistungsdiagnostik und entsprechender Analyseverfahren eingegangen, welche den Ansatzpunkt der informationstechnischen Lösung darstellen.
Daran anschließend werden Methoden der Informatik erörtert, die Einsatz finden könnten, um Fragestellungen der Sportwissenschaft entsprechend zu beantworten. Dabei werden sowohl der Prozess der Trainingsplanung als auch die Modellierung gewonnenen Wissens eine zentrale Rolle spielen.
Einige der gewonnenen Erkenntnisse wurden in Form eines Softwaresystems realisiert, welches zur Automatisierung und zur Unterstützung der Tätigkeiten des Trainers im Hochleistungssport an sportwissenschaftlichen Instituten Einsatz findet.
Abschließend werden die Möglichkeiten und Grenzen der Informatik erörtert und ein Ausblick auf aktuelle und zukünftige Entwicklungen in dieser Sparte gegeben.
1.1
Motivation
Die Informatik hält Einzug in viele Bereiche des Lebens und der Wissenschaft. Durch den Einsatz von Informatiksystemen können Aufgaben und Probleme bewältigt werden, die aufgrund von großen Datenmengen entstehen. Damit auf diesen Daten systematisch Entscheidungen aufgebaut werden können, müssen Methoden zur Datenverwaltung und Datenanalyse zur Verfügung gestellt werden.
Die Sportwissenschaft ist geprägt von einer Vielzahl von Dokumentationsdaten, Messwerten und aus anderen Prozessen generierten Daten, wie in Kapitel 4 noch im Detail erläutert wird.
Ziel ist eine Auswertung dieser Daten, um Grundlagen für Entscheidungen zu erhalten. Diese Entscheidungen können z.B. die Auswahl von Athleten betreffen, die optimale Kombination von Trainingseinheiten, aber auch die Identifikation von sportmedizinischen Wirkungszusammenhängen.
Dank moderner Medizintechnik und dem Einsatz portabler Messgeräte ist eine immer größere Menge von Daten vorhanden. Das ist eine große Chance für Sportwissenschaft und Praxis, da eine breitere Wissensbasis geschaffen werden kann. Allerdings kommt hier das eingangs angesprochene Problem der Bewältigung dieser Datenmengen zum Tragen.
In dieser Arbeit sollen Methoden der Informatik vorgestellt und diskutiert werden, die diesem Problem Rechnung tragen.
1.2
Wirtschaftlichkeit
Auch wenn im Hochleistungssport viel Geld im Umlauf ist, so wird doch noch relativ wenig für die Trainingsplanung und entsprechend auch für Methoden ausgegeben, die diese unterstützen. Es ist auch zu beachten, dass die Zielgruppe nur einen eingeschränkten Personenkreis von Spitzensportlern bzw. deren Trainer umfasst.
Bei Betrachtung der finanziellen Situation ist auch darauf hinzuweisen, dass im Nachwuchsbereich sehr oft die monetäre Unterstützung fehlt. Jedoch ist es genau in diesem Bereich wichtig, Daten über die gesamte Karriereentwicklung eines jungen Athleten bis hin zum Spitzenathleten zu sammeln. Bei entsprechend konsequenter Führung der Aufzeichnungen können interessante Daten für die empirische Untersuchung des Entwicklungsprozesses gewonnen werden [HAMM99].
Der ökonomische Ansatzpunkt in der sportwissenschaftlichen Unterstützungstechnik ist eher im Breitensport zu finden, wo zahlreiche Hobbyathleten mit einem Standardsystem versorgt werden können. Besonders herauszustreichen sind hier wirtschaftliche Erfolge mit Herzfrequenzmessgeräten, die sehr verbreitet sind.
Im so genannten Wellness-Bereich werden immer mehr automatisierte Systeme angeboten, die auf Basis von einigen einfachen Parametern angepasste Trainingspläne für gesundheitserhaltende Aktivitäten bereitstellen. Die Grenzen der Leistungsfähigkeit solcher Systeme sind sehr rasch erreicht, wenn man sich in die Grenzbereiche der Belastbarkeit vorwagt. Hier können Informationssysteme nur mehr zur Unterstützung eines Trainers eingesetzt werden, der die Verantwortung für die Leistung, aber auch für die Gesundheit des Athleten übernimmt.
1.3
Inhaltliche
Abgrenzung
Zentraler Inhalt der vorliegenden Arbeit ist der Einsatz von informationstechnischen Werkzeugen im gesamten Trainingsplanungsprozess. Wie ausgeprägt dieser Trainingsplanungsprozess in der jeweiligen Sportart ist, hängt von der Bedeutung der körperlichen Leistungskomponenten ab (siehe Kapitel 2.2).
Auch die Identifizierung von Simulationsmodellen bildet einen wichtigen Bestandteil der Arbeit. Es sind dazu technische, mathematische und sportwissenschaftliche Prämissen zu diskutieren, die eine solche Modellierung zulassen.
Eine Abgrenzung zu anderen Arbeiten ist vor allem darin zu sehen, dass hier keine Analyse von Taktik oder Technik stattfindet, sondern sich die Betrachtungen rein auf den Bereich der individuellen Leistungssteigerung beschränken.
1.4
Begriffsbestimmungen
In diesem Kapitel werden Begriffe, die im weiteren Text laufend verwendet werden definiert, abgegrenzt und erklärt.
1.4.1 Leistungssport
Def.: "Hochleistungssport ist der auf regionaler, nationaler und internationaler Ebene betriebene Wettkampfsport mit dem Ziel der absoluten Höchstleistung. Hauptkriterien sind Rekorde und internationale Erfolge" (vgl. [RÖT1983] S.337).
Durch diese Definition ist die Abgrenzung zu Gesundheits- und Breitensport gegeben. Dort liegen persönliche Vorlieben und langfristige gesundheitliche Aspekte im Vordergrund.
1.4.2 Trainings-Management
Der Begriff Trainingsmanagement wird in dieser Arbeit als Überbegriff für Trainingsplanung, Diagnostik, Trainingssteuerung und begleitende Tätigkeiten verwendet. Damit soll der Managementprozess beschrieben werden, der mit dem Ziel einer definierten Leistungssteigerung abläuft. Die Einführung des Begriffs Trainingsmanagement findet seine Begründung in der folgenden Charakterisierung:
[SCHW01] beschreibt die Aufgabe des Trainingsmanagement als „die Einhaltung der Begriffsystematik in allen Bereichen und die Installation von klaren Aufbau- und Ablaufstrukturen in allen Bereichen und die Bereiche überspannend.“. Als Bereiche sieht [SCHW01] „Leistungsprognostik, Leistungsdiagnostik, Trainingsplanung, Trainingsdiagnostik und Trainingsauditierung“.
Im Zuge der verstärkten Professionalität der Athleten wurde es auch wichtig, diesen professionellen Charakter in der Unterstützung zu verankern. So ist eine deutliche Wandlung der Trainingswissenschaft festzustellen, von einer „Geheimwissenschaft“ zu modernem Management.
Der Begriff Management scheint auch deshalb zulässig, weil wesentliche Parallelen zu wirtschaftswissenschaftlichen Entscheidungsproblemen aufgezeigt werden können. Die Trainingsplanung ist z.B. mit Ressourcenplanung vergleichbar, dessen Aufgabe es ist, begrenzte Ressourcen in optimaler Allokation einzusetzen um das gesetzte Ziel zu erreichen. Dabei kann es sich bei der Ressource um Trainingszeit, Energie, etc. handeln. Die Analyse von Trainingsdaten und Messwerten findet ihren Konterpart im Controlling wieder. Hier geht es darum, festzustellen ob ein Ziel quantitativ erreicht wurde und Gründe für eventuelle Abweichungen zu finden. Das Auffinden relevanter Informationen wird vor allem im Marketing als „Data-Mining“ bezeichnet und findet sich gleichfalls beim Durchforsten der Datenmengen in der Sportwissenschaft wieder.
In den Wirtschaftswissenschaften sind zahlreiche Publikationen erschienen, die sich mit Managementprozessen beschäftigen und für die vorliegende Problematik zum Auffinden von Lösungsansätzen herangezogen werden. Im speziellen wird auf diese Quellen bei der Datenanalyse zurückgegriffen, insbesondere [ADEL92], [HILD00], [KROE94], [WIED01], [WILB96], [WERN92].
Die Systematisierung des Trainings und der Zwang, sich in bestimmten Strukturen zu bewegen, sollen Ordnung in den Prozess bringen, Zeit sparen und Grundlagen schaffen für die weitere Tätigkeit im Trainingsplanungsprozess. Dabei ist es zu vermeiden, Trainer und Sportler in ihrer „...Individualität, Kreativität, Spontaneität und Innovationskraft...“ zu beschneiden (vgl. [SCHW99]).
1.4.3 Training
Als Training im engeren Sinne wird die Abfolge von Belastung und Erholung verstanden, die zu einer Adaption des Körpers führen (siehe 2.3). Im weiteren Sinne zählen alle Faktoren dazu, die auf die Leistungsentwicklung eines Athleten Einfluss nehmen. Um optimale Ergebnisse zu erzielen, müssen alle oder zumindest möglichst viele dieser Faktoren bei der Planung und Steuerung der Belastungsfolgen berücksichtigt werden (vgl. [SCHW01] und [WEIN96]).
1.4.4 Trainingsplanung
Unter Trainingsplanung wird hier der Vorgang verstanden, in dem der Trainer seine Vorschläge für die nächsten Trainingsreize konkretisiert.
Dieser Plan kann präzise Handlungsanweisungen enthalten oder auch nur als generelle Vorgabe dienen, an der sich der Empfänger (Athlet) orientiert. Trainingsplanung wird in ihrem Ablauf und Ergebnis in 3.4 genau erläutert.
1.4.5 Trainingssteuerung
Unter Trainingssteuerung wird hier die operative Planung und Anpassung des Trainings an aktuelle Umweltbedingungen und körperliche Zustände des Athleten verstanden. Es ist somit eine logische Verfahrensfolge, die aus dem Vergleich von Plan, Prognose und Realität entsteht. Diese Steuerung kann langfristig gesehen werden, indem Leistungsziele angestrebt werden oder auch kurzfristig, um auf diverse Störungen (z.B. Krankheit, Überlastung, etc.) zu reagieren.
1.4.6 Sportmedizin
Im allgemeinen Begriff erstreckt sich die Sportmedizin von der Leistungsdiagnostik über Verletzungsbehandlung bis hin zur Rehabilitation.
In der vorliegenden Arbeit sei der Begriff der Sportmedizin aber auf seine Funktion als unterstützender Faktor innerhalb des Rahmens des Trainingsmanagements beschränkt (vorwiegend Leistungsdiagnostik). Ihr kommt in diesem Zusammenhang in erster Linie die Funktion der Diagnostik zu. Die laufende Weiterentwicklung der Medizin und medizinischer Messverfahren stellt der Sportwissenschaft immer mächtigere und umfangreichere Werkzeuge zur Verfügung. Dadurch wird eine fundamentale Basis geschaffen, die sowohl eine bessere empirische Belegbarkeit sportwissenschaftlicher Modelle als auch eine bessere Kontrolle der eingesetzten Methoden ermöglicht.
2
Sportwissenschaftliche Modelle
Im Folgenden werden kurz die Grundlagen bestehender Modelle angeführt, die als Ausgangspunkt für weitere Überlegungen dienen. Sowohl der Trainingsplanungsprozess als auch unterstützende Modellbildungsmethoden bauen auf diesem Fundament auf.
Der Bezug zur Informatik und Modelltheorie wird hier nur in geringem Ausmaß behandelt. Diesem Thema sind die Kapitel 6 und 7 gewidmet in denen Aspekte der Modellbildung und der Einsatz von mathematischen Modellbildungsverfahren in der Sportwissenschaft zur Sprache kommen.
2.1
Allgemeines
Für eine effektive Trainingsplanung ist es von Bedeutung, die Funktion und Reaktion des Körpers möglichst genau zu kennen. Diese Kenntnis manifestiert sich implizit oder explizit in einem entsprechenden Modell (vgl. auch Kapitel 6 und 7).
Die Funktion des Körpers zu beschreiben ist eine der ältesten Aufgaben der Medizin und der Sportwissenschaft und doch einer derjenigen Sektoren, der noch viele Fragen offen lässt.
Zur Bestimmung der Leistungsfähigkeit sind zahlreiche Variable isoliert worden und für einige stehen auch einfache Messmethoden zur Verfügung. Die Wissenschaft ist jedoch nur begrenzt in der Lage, den tatsächlichen Zustand des menschlichen Körpers genau zu bestimmen.
Wie in Punkt 2.3 zu sehen sein wird, ist genau diese Bestimmung wichtig, um optimale Ergebnisse des Trainings zu erzielen.
2.2
Hauptfaktoren sportlicher Leistung
Die Leistungsfaktoren sind auch zentrale Inhalte des Trainings und daher der zu erfassenden Trainingsdaten. In den letzten Jahren kristallisierte sich vielfach die Methode heraus, die verschiedenen Faktoren getrennt zu trainieren und die Trainingseinheiten direkt auf das zu erreichende Ziel abzustimmen. Das Ziel ist oft auch direkt in der Entwicklung einer bestimmten physischen Komponente des Körpers zu finden.
Die Sportwissenschaft unterscheidet vor allem 4 Hauptfaktoren der sportlichen Leistungsfähigkeit, nämlich Ausdauer, Kraft, Schnelligkeit und Koordination. Je nach Sportart kommen diese Faktoren in Kombination zur Anwendung und manifestieren sich in Form von Kraftausdauer, Schnellkraft, Kraft in Form von Intramuskulärer Koordination, usw. Im Folgenden werden diese Faktoren kurz erklärt und ihre Relevanz in diversen Sportarten dargelegt (vgl. [WEIN96]).
Vorwiegend geht es darum exemplarisch darzulegen, worin Ziele des Trainings liegen. Anhand von Beispielen werden vorhandene Wechselwirkungen dargelegt, um die Komplexität des Systems zu unterstreichen.
2.2.1 Ausdauer
Der Begriff Ausdauer bezeichnet „[...] allgemein die psycho-physische Ermüdungswiderstandsfähigkeit des Sportlers [...]“ (vgl. [WEIN96] S. 163).
Diese sehr allgemeine Definition wird in diverse Arten der Ausdauer gespalten. Die Aufspaltung erfolgt einerseits nach der Komponente Zeit und andererseits nach der Manifestationsform der Bewegung.
2.2.1.1 Manifestationsformen
Es wird unterschieden zwischen organischer allgemeiner Ausdauer und lokaler Muskelausdauer. Je nachdem, welcher Anteil der Skelettmuskulatur bei der Bewegung beansprucht wird, ist der Engpass in der Energie- und Sauerstoffversorgung direkt im Muskel zu finden oder im Herz-Kreislaufsystem.
In Bezug auf die Zeitdauer der Leistungserbringung wird von Lang-, Mittel-, und Kurzzeitausdauer gesprochen. Diese Differenzierung liegt vor allem in der biochemischen Energiebereitstellung begründet. Je nach Art der Energiebereitstellung sind auch verschiedene Organe und Teilsysteme des Körpers beteiligt.
Komplementär zur Belastungszeit verhält sich die Belastungsintensität. Konkret heißt dies, dass eine intensivere Belastung nur über einen kürzeren Zeitraum ausgeführt werden kann, bevor die Ermüdung eintritt.
Aus der Kombination von Zeit und Intensität lässt sich in groben Zügen auch der Energieverbrauch und der entsprechende Bedarf an Nährstoffen ableiten.
In der Gesamtheit der Leistungserbringung tritt die Ausdauer häufig gemeinsam mit den Komponenten Kraft und Schnelligkeit auf. Die entsprechenden Formen werden als Kraftausdauer, Schnelligkeitsausdauer und Schnellkraftausdauer bezeichnet.
Die Komponenten Zeit und Bewegungsform sind jedoch nicht unabhängig voneinander, sondern stehen in einer engen Wechselwirkung.
So ist Kurzzeitausdauer wesentlich enger mit der Muskelausdauer verbunden, während die Langzeitausdauer stärker mit der allgemeinen Ausdauer des Herz-Kreislaufsystems zusammen hängt (vgl. [WEIN96]).
Als Bestimmungsfaktoren für Ausdauerbelastungen können demnach die Größen Zeit und Intensität herausgegriffen werden.
2.2.1.2 Trainingswirkung
Die Wirkung des Ausdauertrainings zielt in erster Linie darauf ab, die Energieversorgung und die Energietransformation zu optimieren.
Die Energieversorgung beruht einerseits auf der Größe von Nahrungsmittelspeichern, die durch das Training erweitert werden. Zum anderen wird eine höhere Transportfähigkeit des Blutes speziell zur Sauerstoffversorgung angestrebt.
Die Transformation der potentiellen Energie in den Nährstoffen in Bewegungsenergie erfolgt im Muskel. Die dafür zuständigen Mitochondrien werden durch Ausdauertraining vermehrt, bzw. es vergrößert sich deren Oberfläche. Dadurch kann mehr Sauerstoff verarbeitet werden und es können größere Mengen an Energie freigesetzt werden.
In diesem Zusammenhang kommt auch wieder der Faktor der Energiebereitstellung zur Sprache.
Die effizienteste und auch ergiebigste Energiequelle sind Fette. Um diese zu verwerten sind jedoch sehr große Mengen an Sauerstoff nötig. Sind die Mitochondrien nicht in der Lage diese Sauerstoffmengen zu verarbeiten, oder wird zu wenig Sauerstoff über die Blutbahn geliefert, so muss die Energie aus Kohlehydraten gewonnen werden. Kohlehydrate stehen jedoch nur in begrenztem Ausmaß zur Verfügung und sind üblicherweise nach 2 Stunden aufgebraucht (vgl. [WEIN96]).
2.2.1.3 Trainingsformen
Die Formen in denen Ausdauertraining durchgeführt wird, lassen sich in 2 große Gruppen unterteilen.
Die Dauermethode ist grundsätzlich durch Belastungsdauer und Belastungsintensität hinreichend spezifiziert. Je nach Sportart oder Trainingsmittel können noch Zusatzangaben nötig sein, wie z.B. die Trittfrequenz im Radsport.
Davon zu unterscheiden sind die Intervallmethode und Wiederholungsmethode. Auch wenn sich diese beiden Typen in ihrer Trainingswirkung unterscheiden, so ist der Aufbau gleich und üblicherweise durch eine Abfolge von Belastungsphasen und Regenerationsphasen gegeben. Der Unterschied liegt im Grad der Erholung zwischen den Belastungseinheiten (vgl. [WEIN96]).
2.2.1.4 Messgrößen
Um die Ausdauerleistungsfähigkeit festzustellen, wurden diverse Messmethoden entwickelt. Eine der verbreitetsten und als genaueste angesehene Größe ist die der maximalen Sauerstoffaufnahme. Diese wird im Zuge eines Leistungstests direkt gemessen oder aus diversen Parametern berechnet.
Für die Kurzzeitausdauer ist auch die Lactatresistenz angeführt. Diese gibt an, bis zu welcher Milchsäurekonzentration der Muskel arbeitsfähig ist.
2.2.2 Kraft
Der Faktor Kraft tritt in zahlreichen Manifestationsformen in Erscheinung. Eine eindeutige Definition ist nur im jeweiligen Zusammenhang möglich (vgl. [WEIN96]).
2.2.2.1 Manifestationsformen
Die Leistungskomponente Kraft kann in zwei Übergruppen geteilt werden, die statische und die dynamische Kraft.
Diese beiden Formen stehen jedoch in einem engen Zusammenhang. Die statische Kraft ist bestimmend für die Ausprägung der dynamischen Kraft.
In der Praxis tritt der Faktor Kraft niemals alleine auf, sondern immer in den Wechselbeziehungen Kraftausdauer, Schnellkraft und Maximalkraft.
Je nach Art der Kraftbeanspruchung wird eine entsprechende Ausprägung der Muskulatur angestrebt.
Der Muskelquerschnitt gibt Aufschluss über die Zahl und Stärke der Muskelfasern.
Die Muskelfasern können wieder nach ihrer Art unterschieden werden in schnellkontrahierende und ausdauernde.
Ein weiterer wesentlicher Faktor ist die „intramuskuläre Koordination“. Koordination bezieht sich auf die harmonische Zusammenarbeit der einzelnen Muskelfasern innerhalb einer Muskelkontraktion (vgl. [WEIN96]).
2.2.2.2 Trainingswirkung
Die Wirkung der kraftorientierten Belastungen ziehen Veränderungen in den Ausprägungsformen des Muskels mit sich, die in Punkt 2.2.2.1 beschrieben wurden.
Ebenso wie die Kraft selbst in vielen Ausprägungsformen auftritt, kann auch das Krafttraining sehr unterschiedliche Formen aufweisen. So kann durch spezifisches Training eine Vergrößerung des Muskelquerschnittes erreicht werden.
Durch Kraftausdauertraining verlängert sich die Zeitspanne, über die eine gewisse Kraft gehalten werden kann.
Langfristig kann das Verhältnis von schnellen und ausdauernden Muskelfasern verschoben werden. Die Tatsache zeigt auch, dass die Entwicklung der Schnellkraft ab einem gewissen Entwicklungsniveau nur mehr auf Kosten der Ausdauerleistungsfähigkeit möglich ist (vgl. [WEIN96] und [LIND93]).
2.2.2.3 Trainingsformen
Der Begriff „allgemeines Krafttraining“ hat sich in der Praxis für das Training an Geräten mit Gewichten durchgesetzt. Dies ist die klassische Form des Krafttrainings, bei dem eine Anzahl von Sätzen mit einer gewissen Wiederholungszahl und Gewicht und bestimmten Geräten durchgeführt wird. Je nach Ausprägung dieser Parameter zielt das Training auf eine bestimmte Entwicklung der Muskulatur ab.
Im Gegensatz dazu wird „spezifisches Krafttraining“ direkt auf dem jeweiligen Sportgerät der Hauptsportart des Athleten durchgeführt. (vgl. [LIND93]) In einigen Sportarten ist hier auch eine ausgeprägte Überschneidung mit den Faktoren Ausdauer oder Schnelligkeit zu erkennen. Beim spezifischen Krafttraining kommt häufig die Wiederholungsmethode zum Einsatz, die auch im Ausdauertraining zu finden ist (siehe 2.2.1.3).
2.2.2.4 Messgrößen
Zur Messung der Kraftleistungsfähigkeit werden vielfach Maximalkrafttests eingesetzt.
Die Ergebnisse dieser Tests werden dann als Berechnungsbasis für die Intensitätssteuerung des Trainings herangezogen.
Die Anzahl von Sätzen und Wiederholungen sind zwar keine direkten Messgrößen für die Kraft, sind aber wesentliche Variable, um ein Krafttraining zu charakterisieren. In der Praxis werden die Wiederholungszahlen direkt einer Trainingswirkung zugeordnet (vgl. [LIND93]).
2.2.3 Schnelligkeit
„Schnelligkeit ist die Fähigkeit, aufgrund der Beweglichkeit der Prozesse des Nerv-Muskel-Systems und des Kraftentwicklungsvermögens der Muskulatur motorische Aktionen in einem unter den gegebenen Bedingungen minimalen Zeitabschnitt zu vollziehen.“ (vgl. [FREY77], S. 349).
2.2.3.1 Manifestationsformen
Schnelligkeit kann unterschieden werden nach der Phase in der Bewegungsfolge, in der sie auftritt.
Die erste Phase reicht vom Zeitpunkt des Auftretens eines äußeren Reizes bis zum Auslösen der Bewegung. In dieser Phase wird von Reaktionsschnelligkeit gesprochen. Als praktisches Beispiel kann die Reaktionsschnelligkeit eines Torhüters beim Elfmeter genannt werden.
In der nächsten Phase ist die Schnelligkeit einer Bewegungsabfolge ausschlaggebend. Diese kann sowohl azyklisch (z.B. Kugelstoßen) oder auch zyklisch ausgeführt werden (z.B. Sprint). Bei der zyklischen Ausführung ist die Zielgröße eine möglichst hohe Bewegungsfrequenz, während die azyklische Bewegung in einer einmaligen, maximalen Muskelkontraktion resultiert.
Da es immer darum geht, einen mehr oder weniger großen Widerstand in kurzer Zeit zu überwinden, spielt der Faktor Kraft eine wesentliche Rolle.
Zusätzlich ist die Koordination des Zentralnervensystems und des intramuskulären Nervensystems eine Vorraussetzung für die Schnelligkeit.
Bezüglich der Struktur der Muskulatur favorisieren schnelle Muskelfasern natürlich die Schnelligkeit, während langsame, ausdauernde Muskelfasern nicht in der Lage sind, eine bestimmte Bewegungsfrequenz zu überschreiten.
2.2.3.2 Trainingswirkung
Je nach Manifestationsform ist genau zu unterscheiden, ob die maximale Schnelligkeit in Reinform trainiert werden soll oder eine Kombination aus Schnelligkeit und Kraft (Schnellkraft) oder Schnelligkeit und Ausdauer (Schnelligkeitsausdauer).
Die maximale Schnelligkeit zielt auf eine optimale Koordination der gesamten Nervenbahnen ab. Im Gegensatz dazu ziehen die Kombinationen immer mehr den Muskel und dessen Kraftfähigkeit bzw. dessen Ausdauer- und Erholungsfähigkeit mit ein.
Als Beispiele für Schnellkraft sind vor allem Wurf- und Sprungsportarten zu nennen, Schnelligkeitsausdauer ist wesentlich für den Sprint und isolierte Schnelligkeit ist als Reaktionsgeschwindigkeit bei Kampfsportarten zu finden (vgl. [WEIN96]).
2.2.3.3 Trainingsmethoden
Ähnlich wie beim Krafttraining ist auch hier die Wiederholungsmethode dominierend. Beim Training der Schnelligkeitsausdauer kann auch die Intervallmethode zum Einsatz kommen.
Hier sei nochmals die negative Wechselwirkung angesprochen, die zwischen allgemeiner Muskelausdauer und Schnelligkeit besteht.
2.2.3.4 Messgrößen
Als Maß für die Schnelligkeit wird meist die Bewegungsfrequenz herangezogen.
Schnellkrafttraining basiert auf den gleichen Parametern wie das Krafttraining, ist jedoch um die Bewegungsgeschwindigkeit erweitert.
2.2.4 Koordination
„Allgemein ist unter Koordination das Zusammenwirken von Zentralnervensystem und Skelettmuskulatur innerhalb eines gezielten Bewegungsablaufes zu verstehen.“ (vgl. [WEIN96]).
Der Faktor Koordination ist im Sport verantwortlich für einen ökonomischen Ablauf der Bewegungen. Vielfach wird auch von Technik gesprochen, die sehr stark an die jeweilige Sportart und das Sportgerät gebunden ist.
Der Einfluss der Koordination auf die Wettkampfleistung variiert sehr stark mit der Sportart. Während z.B. beim Turnen die koordinativen Fähigkeiten eine zentrale Stellung einnehmen, nimmt ihr Einfluss bei Ausdauersportarten ab. Vielfach ist die Koordination ein begleitender Faktor, um die Bewegung zu optimieren.
Nur selten ist dieser Faktor direkt messbar und wird meist auch nicht unmittelbar in Modellüberlegungen einbezogen.
Ein tatsächlicher Einfluss der Koordinationsfähigkeiten auf höhere Leistungsfähigkeiten ist jedoch empirisch belegt (vgl. [WEIN96]).
Der Einfluss ist speziell am Beginn der sportlichen Tätigkeit groß, wenn die Bewegung erlernt wird und mit jeder Durchführung eine koordinative Ökonomisierung verbunden ist. Wenn dieser Einfluss nicht berücksichtigt wird, wird die organische Leistungsentwicklung verfälscht eingeschätzt.
Messmethoden werden in der Literatur kaum genannt. Intuitiv betrachtet kommt eine Rangbewertung durch den Trainer oder den Athleten selbst in Frage.
2.2.5 Weitere Faktoren
Im Wettkampf spielen noch zahlreiche andere Faktoren eine Rolle.
2.2.5.1 Psychische Faktoren
Die körperliche Leistungsbereitschaft hängt mit dem psychischen Zustand des Athleten eng zusammen. Dieser kann Motivation betreffen oder die Konzentration auf die Aktivität.
Aber auch die gesamte psychische Ausgeglichenheit und das Wohlbefinden wirken sich auf das physische Leistungsvermögen und damit auf Wettkampfergebnisse aus.
In der sportwissenschaftlichen Praxis haben sich Rangskalen zur Selbstbewertung durchgesetzt.
2.2.5.2 Beweglichkeit
Ähnlich der Koordination ist die Beweglichkeit eine Art Hygienefaktor für optimale und ökonomische Bewegungsabläufe.
Um die Beweglichkeit zu verbessern werden Dehnübungen durchgeführt. Es ist jedoch keine Einigkeit in der Wissenschaft über die Wirksamkeit solcher Übungen zu finden.
Quantitativ sind Dehnübungen relativ einfach in ihrer Dauer und Häufigkeit bestimmbar, wodurch eine empirische Überprüfung der Wirksamkeit möglich sein sollte.
2.2.5.3 Taktik
Taktische Fähigkeiten sind generell unabhängig von der körperlichen Leistungsfähigkeit und stellen eine additive Komponente im Wettkampf dar.
Zu diesem Punkt sei auf die Arbeit von [GRUB99] verwiesen, in der diese Komponente ausführlich beschrieben und ein informationstechnischer Zugang hergestellt wird.
2.3
Dynamik und Leistungssteigerung
Grundlage des sportlichen Trainings ist die Adaption des Körpers an gesteigerte Belastungen. So ist mit zunehmenden Belastungen und den anschließenden Anpassungsprozessen eine immer größere Belastungsverträglichkeit bzw. Leistungsfähigkeit zu verzeichnen.
Im Folgenden werden diesbezügliche Aspekte und Besonderheiten diskutiert und deren Einfluss auf die Modellbildung. (vgl. [WEIN96], [LIND93).
2.3.1 Adaption
Aufgrund der Anpassungsfähigkeit des menschlichen Körpers an veränderte Umstände ist durch Training eine Erhöhung der Leistungsfähigkeit möglich. In der Medizin und Sportwissenschaft wird dieser Prozess der Adaption auch oft als Superkompensation bezeichnet. Es wird davon ausgegangen, dass durch Belastungen und die folgende Ermüdung eine vorübergehende Minderung der Leistungsfähigkeit auftritt. Nachdem der Erholungsprozess eingesetzt hat, gleicht sich die Leistung wieder an den Ausgangszustand an und läuft etwas darüber hinaus. Auf diese Weise ist der Körper in einer ähnlichen Situation besser vorbereitet. Von diesem ursprünglichen Schutzmechanismus wird für den Leistungsaufbau im Leistungssport systematisch Gebrauch gemacht.
2.3.2 Sättigung
Im Modell der Sportwissenschaft wird davon ausgegangen, dass eine höhere Belastung auch eine größere Anpassungswirkung zeigt. Diese Abhängigkeit ist nur begrenzt gültig und führt ab einem gewissen Niveau zu einer Sättigung. Das bedeutet, dass nur mehr geringe Leistungssteigerungen erreicht werden können, auch wenn hoher Aufwand betrieben wird. Dadurch wird das Training zusehends unökonomischer.
Betrachtet man die verschiedenen Faktoren der Leistungserbringung, so sind zwischen diesen dispositive Entscheidungen zu treffen. Da jedem Athleten nur eine begrenzte Menge an Zeit und Energie zur Verfügung steht, hat die Sättigung einen wesentlichen Einfluss auf die Verteilung der Belastungsreize um eine ideale Ausprägung aller Faktoren zu erreichen.
Im Sport wird dabei auch von Spezialisierung gesprochen. Während Sportler in einer frühen Entwicklungsphase, alle ihre Fähigkeiten ausbauen können, muss sich ein Spitzensportler für einen bestimmten Ausschnitt seiner Sportart entscheiden, um dort in die Weltspitze vordringen zu können.
2.3.3 Wechselwirkungen
Es nicht nur so, dass eine Sättigung eines der Faktoren auftritt, sondern auch erwünschte oder unerwünschte Wechselwirkungen existieren. Gewünscht können gegenseitige Verstärkungen oder Kompensationswirkungen sein. So kann z.B. Ausdauertraining bei einem austrainierten Athleten keinen unmittelbaren Effekt mehr haben, dient aber zur Kompensation anderer Belastungsformen und ist daher trotz der Sättigung im jeweiligen Zielbereich ein wesentlicher Bestandteil des Trainings.
Andererseits bestehen zwischen Kraft, Schnelligkeit und Ausdauer teilweise negative Korrelationen (siehe 2.2). Beispielsweise kann durch intensives Kraft- und Schnelligkeitstraining eine Strukturverschiebung im Muskel von schnellen zu ausdauernden Muskelfasern erreicht werden. Folglich ist die Steigerung der Schnelligkeit mit einem Absinken der Ausdauer verbunden.
2.3.4 Überlastung
Wurden vorhin bereits die begrenzten Ressourcen wie Zeit und Energie angesprochen, kommt man zu einem Phänomen, welches als Überlastung oder Übertraining bezeichnet wird.
Hier ist nicht nur eine Sättigung, sondern sogar eine rückläufige Entwicklung zu verzeichnen. In diesem Bereich wird die Definition bzw. Beschreibung des Modells immer ungenauer und weniger deterministisch. Die Reaktion auf eine Überlastung ist nur sehr schwer abschätzbar und kann verschiedene Ausprägungsformen aufweisen. Ist das verträgliche Niveau von Belastung überschritten, greifen vielfach natürliche Schutzmechanismen ein, die einen Abbruch der Tätigkeit erzwingen. Diese können sich in Form von Krankheiten, Verletzungen oder auch psychischen Problemen manifestieren und verändern das gegebene System so radikal, dass ein verifiziertes Modell seine Gültigkeit verliert.
Natürlich überschreiten dort, wo die Erklärbarkeit durch die spezielle Wissenschaft nicht mehr möglich ist, auch die Modellbildung und Informatik ihre Möglichkeiten.
Zusammenfassend ist zu sehen, dass das Modell der Leistungsanpassung in der Praxis im Hochleistungssport immer in einem Grenzbereich agieren muss, um die höchst mögliche Ausreizung zu erreichen.
Diese Gratwanderung stellt besondere Anforderungen an eine Modellbildung.
2.3.5 Optimierung
Die Herausforderung in diesem Prozess ist das Auffinden der genauen Dosierung der Trainingsreize sowie des richtigen Zeitpunktes. Wird der nächste Belastungsreiz zu bald gesetzt, ist noch keine ausreichende Erholung gegeben und das Training kann seine Wirkung nicht entfalten oder provoziert Überlastungen. Erfolgt das Training zu spät, ist bereits wieder ein Rückgang des Superkompensationseffektes zu verzeichnen, bzw. es wird wertvolle Zeit für den Leistungsaufbau nicht genutzt.
2.3.6 Regeneration
Wie in den vorhergehenden Abschnitten dargestellt wurde, findet die eigentliche Leistungssteigerung in der Phase der Erholung statt. Daher kommt diesem Faktor eine immer größere Bedeutung zu (vgl. [WEIN96]).
Regeneration bedeutet eine Wiederherstellung der Homöostase (Ausgeglichenheit) im Körper nach der Belastung.
Um eine optimale, schnelle und vollständige Erholung zu ermöglichen, werden im Hochleistungssport spezielle Maßnahmen gesetzt. Dabei wird zwischen aktiven und passiven Regenerationsmaßnahmen unterschieden.
Aktive Maßnahmen sind durch aktive Beteiligung der Muskulatur charakterisiert. Dazu zählen „Auslaufen“, Gymnastik und Dehnen oder leichte Spiele. Sie stellen also einen Teil des aktiven Trainings dar, haben aber eine regenerative und keine belastende Wirkung.
Im Gegensatz dazu sind passive Maßnahmen nicht immer unmittelbar der sportlichen Betätigung zurechenbar. Eine der wichtigsten Faktoren der passiven Regeneration ist der Schlaf. Sowohl Qualität als auch Quantität des Nachtschlafes haben großen Einfluss auf die Erholung. Zusätzlich können Massagen und Sauna positive Wirkung auf die Regeneration haben (vgl. [WEIN96]).
In der Literatur werden auch mentale und psychische Regenerationsmaßnahmen beschrieben. So hat nach [WEIN96] das „autogene Training“ eine wesentliche Verkürzung der Regenerationszeit zur Folge. Durch psychische Maßnahmen kann auch Stress während oder zwischen Wettkämpfen reduziert werden.
2.3.7 Dynamische Komponenten
Die Leistungsentwicklung folgt keiner streng monoton steigenden Funktion, sondern ist durch eine Reihe von überlagerten Einflüssen charakterisiert. Für die langfristige Leistungssteigerung wird ein positiver Trend vorausgesetzt. .
Die jährliche Leistungssteigerung ist nicht konstant, sondern kann von Jahr zu Jahr variieren.
Innerhalb eines Jahres sind natürliche saisonale Schwankungen zu verzeichnen, die ihren Grund vorwiegend im Erholungsbedarf des Körpers haben.
Zusätzlich wird das Trainingsjahr häufig in Mesozyklen unterteilt, die 3 bis 6 Wochen umfassen. (siehe 3.4.2). Innerhalb dieser Zyklen ist üblicherweise ein Leistungshöhepunkt zu finden, der mit wichtigen Wettkämpfen synchronisiert wird (vgl. [LINDER93]).
saisonale Schwankungen Trend Zeit Leistung
![]()
![]()
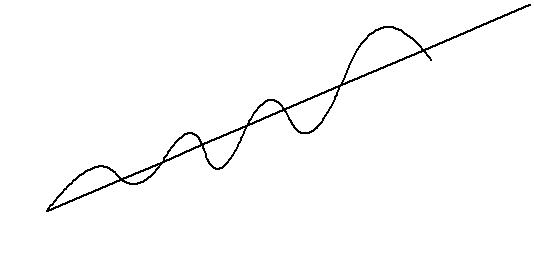
Abbildung 1: dynamische Komponenten und Trend
2.3.8 Modelldynamik
Das Modell ist nicht nur durch die beschriebenen dynamischen Komponenten charakterisiert, sondern ist auch selbst Veränderungen unterworfen. Da die Entwicklung nicht vollständig vorhersehbar ist, müssen die Modellparameter ständig an die tatsächlichen Gegebenheiten angepasst werden, um gültige Ergebnisse zu erhalten. Betrachtet man die enormen Unterschiede zwischen jungen Nachwuchssportlern und Profis (vgl. [WEIN96], [LIND93], ist zu vermuten, dass nicht nur die Modellparameter variieren, sondern eine komplette Strukturanpassung der Modelle erforderlich ist.
3
Sportwissenschaftliche Praxis
In diesem Kapitel soll die sportwissenschaftliche Praxis in ihren Grundzügen durchleuchtet werden. Auf ihr bauen weitere Überlegungen speziell zur Implementierung eines Softwaresystems auf, welches sowohl die operative Tätigkeit, als auch die Entscheidungsprozesse unterstützen soll.
Zu diesem Zweck wird erläutert, auf welcher Basis in der sportwissenschaftlichen Praxis Entscheidungen getroffen werden und wie verbreitete Vorgehensmodelle aussehen.
3.1
Entscheidungsbasis
Jeder Entscheidung liegen Fakten und Daten zugrunde. Dies bedeutet noch nicht, dass diese Grundlagen systematisch aufgearbeitet, bewertet und abgewogen werden. Speziell in der Sportwissenschaft sind vielfach intuitive Entscheidungen zu finden. Diese Beschreibung soll keineswegs eine negative Darstellung dieser Tatsache bedeuten. Ganz im Gegenteil, es sind viele Entscheidungsträger in der Lage, neben dem bewussten Einsatz ihres Wissens unbewusst auf Erfahrungen der Vergangenheit zurückzugreifen. Da dieses Wissen und die Erfahrungen nie vollständig erfasst und formalisiert werden können, kommt dem Faktor Mensch wieder eine gehobene Bedeutung zu und lässt die Technik bzw. Automatisierung ihre Grenzen erreichen.
Dennoch ist eine gewisse systematische Aufarbeitung vorhandener Daten als Hilfe anzusehen, die zusätzliche Informationen in den kreativen Prozess der Planung einbringen können. Diese Informationen sind in dem Datenberg sozusagen „begraben“, wodurch in den Wirtschaftswissenschaften sehr häufig der Begriff des „Data-Mining“ (siehe 7.1) verwendet wird.
In den letzten Jahren ist ein rapider Fortschritt der medizinischen Messtechnik zu verzeichnen, wodurch diese Techniken wesentlich häufiger zum Einsatz kommen und auch kleineren Instituten zugänglich werden. Neue Messverfahren machen es möglich, immer größere Datenmengen in immer kürzeren Intervallen zu gewinnen. Einige Aspekte zu diesem Thema werden in Kapitel 4 noch eingehender besprochen.
3.1.1 Leistungsdiagnostik
Seit langer Zeit in Verwendung ist die Methode, aufgrund von normierten Leistungstests den aktuellen physischen Status des Athleten zu ermitteln. Dabei kommen die in 4.4 beschriebenen Testmethoden zum Einsatz. Um die Leistungsentwicklung beurteilen zu können, sind Tests über einen längeren Zeitraum hinweg durchzuführen. Da die Ergebnisse miteinander vergleichbar sein müssen, sind immer die gleichen Methoden anzuwenden. Allerdings unterscheiden sich diese sehr stark zwischen den verschiedenen Sportarten.
3.1.2 Sportmedizinische Messwerte
In der sportwissenschaftlichen Praxis hält vor allem im Hochleistungssport immer mehr die regelmäßige medizinische Betreuung Einzug. Einen wesentlichen Teil davon stellt die laufende Aufnahme und Kontrolle medizinischer Daten und Parameter dar. Für Details sei auf 4.3 verwiesen.
3.1.3 Wettkampfergebnisse
Für den strukturierten Trainingsmanagementprozess sind Wettkampfergebnisse wichtig, da sie das eigentliche Ziel des Trainings darstellen. Im Wettkampfergebnis fließen neben den körperlichen Fähigkeiten auch psychische und taktische Faktoren mit ein.
Aufgrund der vielfältigen Einflussfaktoren ist es schwierig, Ursachen für die Leistung zu isolieren. In der Praxis werden Wettkampfergebnisse über längere Zeiträume mit Leistungstests verglichen und so auf Ursachen rückgeschlossen.
3.1.4 Subjektive Wahrnehmung
Wie eingangs erwähnt, haben die Intuition und das Gefühl einen großen Stellenwert in der Beurteilung der aktuellen Situation. Sowohl der Trainer, als auch der Athlet entwickeln im Laufe der Zeit eine entsprechende Sensibilität. Diese Daten sind nicht messbar und sehr schwer dokumentierbar.
Es kann natürlich nicht Aufgabe eines Unterstützungssystems sein, diese zusätzlichen Informationen zu eliminieren, weil sie nicht verarbeitet werden können. Vielmehr muss der entsprechende Spielraum geboten werden, in dem dieses Potential umgesetzt werden kann.
3.2
Vorgehensmodelle der Sportwissenschaft
Dieses Kapitel stellt eine kurze Zusammenfassung von aktuell verwendeten Vorgangsmodellen bei der Trainingsplanung und Trainingssteuerung dar. Meist sind die Prozesse nicht einer Kategorie zuzuordnen, sondern beinhalten mehrere Sichtweisen.
Quellen sind vorwiegend Gespräche mit Trainern über praktische Erfahrungen. In der Literatur ist eine explizite Beschreibung des Trainingsplanungsprozesses kaum zu finden.
3.2.1 Versuch und Irrtum
Aufgrund der Individualität des Athleten und der Unsicherheit über den aktuellen Zustand sind erste gemeinsame Schritte von Trainer und Athlet oft mit Versuch und Irrtum verbunden. Der Trainer muss langsam erkennen, auf welche Methoden der Athlet anspricht und welche Belastungsverträglichkeit er mitbringt.
Selbst wenn fundierte Tests und Analysen durchgeführt werden, so bleibt doch immer ein gewisser Spielraum. Genau dieser Grenzbereich muss jedoch ausgelotet werden.
3.2.2 Intuitiv
Als intuitive Methode soll hier verstanden werden, dass auf jegliche Messmethoden verzichtet wird und das Training „nach Gefühl“ geplant und gesteuert wird. Speziell von Trainern und Athleten, die schon seit langer Zeit eine Sportart betreiben, wird diese Methode vielfach mit großem Erfolg angewandt.
Hier gilt das gleiche wie bei „Versuch und Irrtum“. Auch wenn Daten vorliegen und das Training grundsätzlich auf diesen Daten aufgebaut wird, ist es unerlässlich die Intuition ins Spiel zu bringen. Es liegen immer Einflussfaktoren vor, die nicht vollständig erfasst und operationalisiert werden können.
Die Aufgabe, die Intuition einzubringen, obliegt sowohl dem Trainer, der seinen Athleten kennen sollte, als auch dem Athleten selbst, der eine gewisse Selbstverantwortung tragen muss.
Genau dieser Punkt ist es auch, der einer Automatisierung und auch der elektronischen Kommunikation noch Grenzen setzt. Der persönliche Kontakt zwischen Trainer und Athlet ist unabdingbar.
3.2.3 Diagnostikbasiert
Von diagnostikbasierter Trainingsplanung kann gesprochen werden, wenn diese rein auf Basis von Leistungsdiagnostik und der Beobachtung medizinischer Parameter erfolgt.
Der Plan wird nach wie vor von einem Trainer erstellt, der seine Erfahrung und seine Intuition einfließen lässt.
Im Breitensport findet diese Methode verbreiteten Einsatz. Dort ist einerseits der enge persönliche Kontakt zum Athleten nicht immer gegeben und zum anderen darf dem Breitensportler nicht zu viel Eigenverantwortung zugemutet werden. Dieser kennt seinen eigenen Körper nicht so genau wie ein Profiathlet und hat daher nicht die Erfahrung, um selbst zu sehr in den Plan eingreifen zu können.
Zudem nähert man sich im Breitensport nicht so weit den körperlichen Grenzbereichen, wodurch immer eine gewisse Sicherheitsreserve gegeben ist.
3.2.4 Automatisch
Mit dem Begriff „automatische Planung“ soll ausgedrückt werden, dass am unmittelbaren Trainingsplanungsprozess keine Person mehr beteiligt ist. Dieser Prozess wird rein automatisch von einem EDV-System durchgeführt.
Auch hierfür gibt es Beispiele im Breitensport. Es werden Standardpläne anhand der ermittelten Parameter individuell angepasst. Anbieter dieser Methoden sind im Internet zu finden. Durch die Beantwortung einiger Fragen zum persönlichen Leistungszustand ermittelt ein Programm den optimalen Trainingsplan.
(Beispiele: http://homepage.sunrise.ch/homepage/spin07/trplan1.htm,
Im Hochleistungssport sind derartige Systeme mit erheblichen Schwierigkeiten verbunden und vermutlich nur bedingt einsetzbar (vgl. 13.3).
3.3
Abschätzung der Belastung
Es ist wesentlich, festzustellen, wie stark eine Belastung auf die Ermüdung des Körpers wirkt um abschätzen zu können, wann die nächste Trainingseinheit gesetzt werden kann bzw. muss um eine optimale Leistungsentwicklung zu erreichen (siehe 2.3).
Hier sind einige Methoden angeführt, die vor allem auf praktischen Erfahrungen beruhen und nicht unbedingt wissenschaftlich fundiert sind.
3.3.1 Erholungszeiten
Bei einer vielfach verwendeten Methode zur Abschätzung der Trainingsbelastung, wird vereinfachend angenommen, dass jede Trainingsform ab einer gewissen Dauer eine bestimmte Regenerationszeit erfordert. Diese Thesen werden auch in der Literatur häufig vertreten (vgl. [LIND93], [WEIN96]).
Beispielhaft sieht eine solche Beschreibung so aus:
Erholungszeiten nach „Grundlagentraining“:
- bis 1 Stunde – keine ermüdende Wirkung
- 1 Stunde bis 3 Stunden – Regeneration 12 h
- ab 3 Stunden – Regeneration 24 h
Ein Nachteil dieser Methode ist, dass individuelle Unterschiede weitgehend außer Acht bleiben. Die Erholungsfähigkeit hängt stark von der Person und ihrem aktuellen Zustand ab.
Die Qualität der Regeneration wird zusätzlich von entsprechenden Maßnahmen bestimmt (siehe 2.3.6).
3.3.2 Belastungsfaktoren
In manchen Trainingssoftwaresystemen ist eine Methode implementiert, die verschiedenen Trainingsbereichen Belastungsfaktoren zuordnet. Diese Faktoren werden mit der entsprechenden Belastungszeit in diesem Trainingsbereich multipliziert und daraus ein verbesserter Belastungswert abgeleitet.
Primäres Ziel ist eine Gewichtung der Trainingszeiten und damit eine bessere Abschätzung der Gesamtbelastung in einer Periode. Vielfach erfolgt die Einteilung der Belastungsfaktoren über Herzfrequenzbereiche, wie z.B. beim Trainingsprotokollsystem der Firam „Polar“. Die Bestimmung der Faktoren ist meist individuell möglich und oft an die Lactatwerte eines spiroergometrischen Tests angelehnt.
Beispiel:
|
Trainingsbereich |
Herzfrequenz |
Lactat |
Faktor |
|
Regeneration |
< 120 |
< 0,7 |
-0,5 |
|
Grundlagentraining |
120-140 |
0,7 – 1,0 |
0,8 |
|
Grundlagentraining 2 |
140 – 160 |
1,0 – 2 |
1,5 |
|
Entwicklungsbereich |
160 – 175 |
2 – 4 |
4 |
|
Maximaltrainings |
>175 |
> 4 |
7 |
Tabelle 1 Trainingsbereiche und Belastungsfaktoren
Dieses Verfahren ist sehr einfach implementierbar und eine hervorragende Methode zur groben Abschätzung von Belastungssummen. Eine Schwäche ist jedoch die angenommene Linearität, die bei der Berechnung der Belastung offensichtlich unterstellt wird.
Die in 2.3.2 erwähnte Sättigung ab einer gewissen Schwelle (Intensität oder Zeit) bleibt völlig unberücksichtig. Ebenso ist es schwierig, eine kurzfristige Überlastung (siehe 2.3.3) abzuschätzen. Dieses Manko wäre durch die Einführung von Schwellwerten in der Berechnungsformel relativ einfach zu beheben.
Da die Trainingseinheiten getrennt betrachtet werden, können auch keine Wechselwirkungen berücksichtig werden (siehe 2.3.4). Dazu wären komplexere Berechnungsalgorithmen nötig, die zur Berechnung einer einzelnen Belastungseinheit, auch die vorhergehenden Einheiten mit einbeziehen.
Eine Alternative ist eine ständige Schätzung des Zustandes, in dem sich der Athlet durch die Belastung befindet.
3.3.3 Zustandsbestimmung
Durch äußere Einwirkungen, wie körperliche Belastungen, findet eine Zustandsänderung des Systems „menschlicher Körper“ statt. Durch die Messung von medizinischen Werten und die Selbstkontrolle (siehe 4.3) wird versucht, auf den aktuellen Zustand rück zu schließen.
In diesem Bereich könnte die Informatik mit Analysemethoden und Methoden zur Modellbildung eingesetzt werden, um eine möglichst genaue Abschätzung des Zustandes auf Basis einer breiten Datenmenge zu ermöglichen. In Kapitel 7 werden entsprechende Methoden, deren theoretischer Hintergrund und mögliche Anwendungen diskutiert.
3.4
Trainingsplanungsprozess
Ein zentraler Punkt dieser Arbeit stellt die Trainingsplanung und vor allem die computertechnische Unterstützung dieser Phase dar.
Der Prozess läuft mehrstufig und relativ gut strukturierbar ab, wodurch sich ein interessanter Ansatzpunkt bietet um Abläufe zu optimieren und zu automatisieren.
3.4.1 Langfristige Planung
Der menschliche Körper als Subjekt im Sport unterliegt im Laufe der Zeit bestimmten Änderungen. Auf diese muss bei der Erstellung von Plänen Rücksicht genommen werden. Üblicherweise gliedert sich eine sportliche Karriere in 3 wesentliche Abschnitte. Zu Beginn steht im Jugendalter die unspezifische, allgemeine, athletische Ausbildung. In dieser werden allgemeine sportliche Fähigkeiten geschult und eine Basis gelegt, auf die später aufgebaut werden kann. In dieser Phase erfolgt noch keine konkrete Spezialisierung auf eine gewisse Sportart.
Die nächste Phase ist der Aufbau und die Spezialisierung. Hier wird entschieden, in welcher Sportart die Karriere angestrebt wird und im Weiteren, welche speziellen Fähigkeiten besonders ausgebaut werden sollen. Z.B.: der Sportler entscheidet sich für den Straßenradsport und findet seine Stärken im Sprint.
Ist diese Entwicklung abgeschlossen, so tritt der Athlet in die Höchstleistungsphase ein, in der es in erster Linie darum geht, die erworbenen Fähigkeiten zu erhalten, auszubauen und die Leistung zum richtigen Zeitpunkt erbringen zu können.
Wenn man die Unterschiede der verschiedenen Phasen betrachtet, wird auch klar, warum die Strategien bei der Trainingsplanung nach verschiedenen Gesichtspunkten ausgelegt werden. Während die ersten beiden Phasen sehr langfristig angelegt sind und immer mit Hinblick auf die abschließende Höchstleistungsphase geplant werden, so ist in dieser dann ein kurz- bis mittelfristiger Entscheidungshorizont gegeben.
Auch die Reaktion des Körpers auf Trainingsreize verändert sich im Durchlauf der verschiedenen Entwicklungsstufen. Daher muss ein Modell, welches diese Reaktion repräsentiert, entsprechend angepasst werden, bzw. diesen Veränderungsprozess miteinbeziehen (vgl. [LINDER93]).
3.4.2 Periodisierung
So wie viele natürliche Objekte unterliegt auch der menschliche Körper jahreszeitlich bedingten Schwankungen. Auf den Sport bezogen bedeutet dies, dass sich Abschnitte erhöhter bzw. verringerter Leistungsfähigkeit zyklisch wiederholen. In der modernen Sportwissenschaft werden diese zyklischen Veränderungen nicht nur beachtet, sondern zum eigenen Nutzen verwendet. Das bedeutet in der Praxis, dass das Leistungstief auf einen Zeitpunkt getrimmt werden soll, in dem keine Wettkämpfe auf dem Programm stehen und zum anderen die Phase der Höchstleistung in die Hauptwettkampfperiode gelegt wird.
Die zyklische Anpassung ist durch entsprechende Ausgestaltung des Trainings anpassbar.
Aus diesem Grund wird in der Praxis zuerst ein grober Jahresplan erstellt, in dem alle wichtigen Ereignisse ihren Platz finden, wie Hauptwettkämpfe, Erholungsphase, persönliche Verpflichtungen außerhalb des Sports usw.
Ausgehend davon wird das Jahr in Phasen und Zyklen eingeteilt. Phasen werden durch ähnliche Trainingsinhalte und –ziele charakterisiert. Ein Zyklus beschreibt einen Zeitraum steigender Belastung mit anschließender Erholung (vgl. [LIND93], [WEIN96]).
3.4.3 Die Trainingseinheit
Die kleinste eigenständige Einheit in der Trainingsplanung wird als Trainingseinheit bezeichnet.
3.4.3.1 Allgemeines
Im Zuge von Experteninterviews und Literaturstudium ist es gelungen, eine allgemein gültige Kriterienbank für die Identifikation von Trainingseinheiten zu finden (vgl. auch [SHWARZ99]).
Die Herausforderung bei der Identifikation der Elemente einer Trainingseinheit war vor allem dadurch gegeben, dass zwei konkurrierende Anforderungen befriedigt werden sollten.
Zum ersten war gefordert, eine möglichst hohe Flexibilität zu wahren, um den Einsatz des Systems in verschiedenen Sportarten und auch mit diversen Trainingsphilosophien zu ermöglichen.
Andererseits ist natürlich ein Mindestmass an Standardisierung gefordert, um eine Auswertung und Klassifikation der Einheiten zu ermöglichen.
Als grundlegende Merkmale jeder Trainingseinheit wurden folgende 4 Punkte identifiziert:
3.4.3.2 Trainingskategorie
Der Faktor Kategorie beinhaltet Daten, die spezifisch für die vorliegende Trainingsform sind.
Die dazu gehörenden Informationen spiegeln die Struktur und den Inhalt des vorliegenden Belastungselementes wieder.
3.4.3.3 Trainingsintensität
Ergänzend zu der allgemeinen Struktur der Trainingseinheit werden im Zuge des Faktors Intensität die personenspezifischen Parameter aufgezeichnet.
3.4.3.4 Trainingsmittel
Der Begriff Trainingsmittel ist die allgemeine Umschreibung von Hilfsmitteln und Aktivitäten, mit denen die Trainingseinheit durchgeführt wird. Das können beispielsweise Sportgeräte sein (Fahrrad, Kraftkammer, Ruderboot, ...) oder Bewegungsabläufe (Laufen, Schwimmen, ...).
3.4.3.5 Wirkungsziel
Darunter wird jene Leistungskomponente oder jener Teil des Körpers verstanden, auf welche die primäre Wirkung des geplanten Trainings abzielt. Je nach Trainingsphilosophie kann das Ziel durch ein Organ (Muskel, Herz-Kreislauf, ...) oder eine komplexe Komponente (Ausdauer, Kraft, ...) beschrieben werden.
4
Datengewinnung
Ein wesentlicher Bestandteil der Trainingsplanung und -steuerung ist die laufende Erfassung von Daten und Parametern. Diese bilden die Grundlage für weitere Entscheidungen und stellen daher die Basis eines jeden Trainingssystems dar.
In diesem Kapitel werden einige Methoden zur Ermittlung von Daten aus der Praxis vorgestellt und analysiert. Gleichzeitig wird diskutiert, welche Aufgaben sich dabei für die Informatik ergeben.
4.1
Datenbankzugriff
Ergebnis der Datengewinnung ist die Ablage der gewonnenen Informationen in einer Datenbank. Aus diesem Grund ist eine zentrale Frage der Datengewinnung auch der Übertragungsweg in die Datenbank.
Grundsätzlich kann zwischen online und offline Verbindungen unterschieden werden.
In beiden Fällen ist es wichtig, dass der Athlet bei der Dateneingabe die gleichen Strukturen verwendet wie der Trainer, damit die Daten anschließend einer Analyse unterzogen werden können. Zu diesem Zweck muss darauf geachtet werden, dass alle Teilnehmer des Systems mit einer aktuellen Datenbasis arbeiten.
Im Folgenden werden kurz die spezifischen Vor- und Nachteile der beiden Ansätze aufgezeigt.
4.1.1 Online
Im Falle der Onlineerfassung von Daten werden die Dokumentationsdaten vom Athleten direkt in die Datenbank übertragen. Dies kann z.B. synchron über ein Web-Interface erfolgen.
Synchrone Methoden haben den Vorteil, dass die Datenbank immer konsistent ist. Auch bei der Dateneingabe greift der Athlet auf den gleichen Datenbestand zurück wie der Trainer. Speziell die Definitionsdaten und Strukturdaten sind dann immer auf dem neuesten Stand.
Allerdings sind diese Methoden auch mit den allgemeinen Problemen von Online-Verbindungen und multiplem Zugriff auf Datenbanken verbunden. Dies sind vor allem Datenkorrektheit und Datenschutz.
Ziel eines umfassenden Systems ist es mehreren Athleten und Trainern die Möglichkeit zu geben, ihre Daten darin zu verwalten. Um die Frage des Datenschutzes zu lösen, ist eine detaillierte Vergabe von Zugriffsrechten vorzusehen. Werden nämlich Trainingsdaten den Konkurrenten zugänglich, so kann dies zu einem Verlust eines Wettbewerbsvorteils führen.
Zur Lösung des Problems der Datenkorrektheit und Datenvollständigkeit sind hohe Anforderungen an die Robustheit des Systems zu stellen. Dies betrifft vor allem Methoden, die eine korrekte Datenübertragung über das Netzwerk sicherstellen.
Diese Anforderung ist berechtigt, da der Trainer Entscheidungen auf diesen Daten aufbaut. Bevor die Daten eingetragen werden, muss eine Plausibilitätskontrolle durchgeführt werden und die Dokumentation muss unmissverständlich erfolgen.
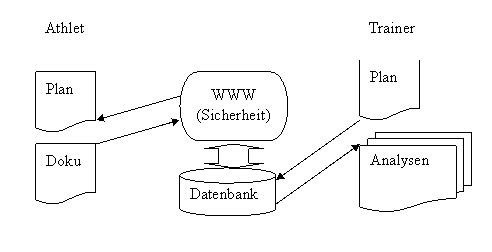
Abbildung 2 Online-Kommunikation
4.1.2 Offline
Werden die Daten nicht direkt in die Datenbank übertragen, so müssen sie zwischengespeichert werden. Die Speicherung kann auf einem lokalen Rechner erfolgen, von wo aus die Aufzeichnungen mit der Zentraldatenbank abgeglichen werden.
Im einfachsten Fall wird die Zwischenspeicherung auf Papier ausgeführt und dann in die Datenbank eingegeben.
Vorteile sind darin zu sehen, dass keine Online-Verbindung der Datenbank nötig ist. Nachteile sind in nicht garantierter Datenkonsistenz zu finden. Werden die Daten synchronisiert, ist zu beachten, dass keine doppelte Aufzeichnung erfolgt.
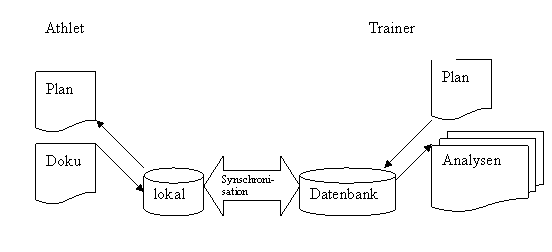
Abbildung 3 Offline-Kommunikation
4.1.3 Entwicklung
Im Zuge der Integration verschiedener Medien können zukünftig auch Pocket-PCs in ein entsprechendes Datenkommunikationssystem einbezogen werden.
Die Tendenz wird eher in Richtung Online-Zugriff gehen, da eine zunehmende Vernetzung den Zugriff auf Internet-Server von beinahe allen Standorten erlaubt. Auch Pocket-PCs und Mobiltelefone bieten immer umfangreichere Möglichkeiten zum Einsatz als Internet-Kommunikationsgeräte.
4.2
Trainingsdaten
Die Aufzeichnung von Trainingsdaten ist eine der Hauptaufgaben im Prozess des Trainingsmanagement. Meist ist eine doppelte Aufzeichnung gewünscht, und zwar in Form eines Plans und einer Durchführungsdokumentation. Um eine Vergleichbarkeit der Daten zu gewährleisten, werden häufig die gleichen Datenstrukturen für Plan und Dokumentation verwendet.
In der Praxis hat sich die Methode durchgesetzt, das komplexe Zusammenspiel im Training auf die kleinste Einheit zu reduzieren, die Trainingseinheit (siehe 3.4.3). In der Regel werden Pläne dann als Liste oder Tabelle von Trainingseinheiten erstellt, wobei viele Trainer in ihren Planungsmethoden bewusst oder unbewusst auf Strukturen relationaler Datenbanken aufbauen.
Andere Methoden der Planung und Dokumentation hat sich in der Sportwissenschaft noch nicht durchgesetzt, könnte aber auf Grundlagen der objektorientierten Programmierung basieren. Vielfach sind Trainingsmethoden sehr ähnlich und unterscheiden sich nur in der Ausprägung verschiedener Parameter.
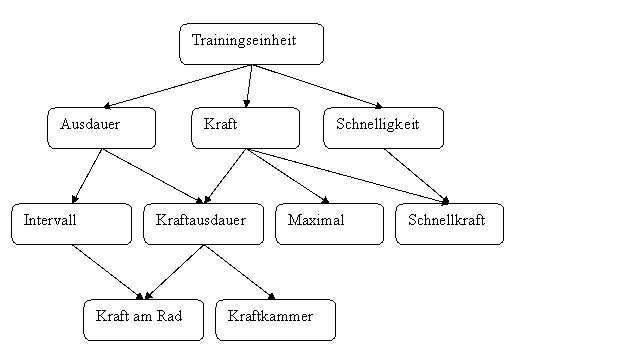
Abbildung 4 Klassendiagramm von Trainingsmethoden (unvollständig und vereinfacht)
Des Weiteren sind Trainingseinheiten nicht nur als Einzeleinträge zu sehen, sondern bilden erst in ihrem Verbund zu größeren Objekten (Wochen- und Meso-Zyklen) eine wirksame Einheit (siehe 3.4.2).
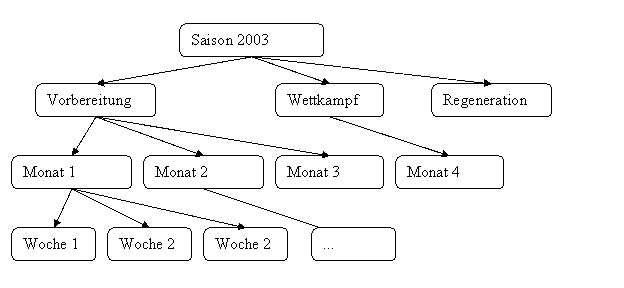
Abbildung 5 Hierarchische Struktur der Periodisierung
4.2.1 Grunddaten
Über die Grunddaten wird die Trainingseinheit in ihrer Charakteristik beschrieben. Es sind dies Informationen, die für jede Trainingseinheit relevant sind (siehe 3.4.3).
Es wird zuerst definiert, auf welcher Struktur das Training basiert. Dieser Teil wird als Kategorie bezeichnet, aufgrund derer sich dann die kategoriespezifischen Daten ergeben, welche genaue Durchführungsbeschreibungen darstellen. Die Kategorie repräsentiert somit die Trainingsmethode.
Weiter ist angegeben, in welchem Intensitätsbereich das Training durchgeführt wird. Dieser kann durch verschiedene Parameter definiert werden. Beim Ausdauertraining werden üblicherweise Herzfrequenzbereich oder Lactatwerte angegeben. Beim Krafttraining kann das Verhältnis zur Maximalkraftfähigkeit angegeben werden. Ergometertraining wird teilweise mit direkter physikalischer Leistung in Watt angegeben. Die Ausprägungsformen sind mannigfaltig und hier nur exemplarisch angeführt.
Einen weiteren Faktor, der für jede Trainingseinheit relevant ist, stellt das Mittel zur Durchführung dar. Der Begriff ist sehr weitreichend zu sehen, da beim Lauftraining das Mittel ganz einfach das „Laufen“ als Bewegungsform definiert und beim Krafttraining andererseits die Kraftkammer oder ein spezifisches Gerät gemeint sein können.
Zuletzt ist das Training meist darauf ausgerichtet, einen der Hauptfaktoren (siehe 2.2) bzw. ein Zielorgan zu entwickeln. Dabei kann es sich sowohl um die Angabe eines Leistungsfaktors oder auch eines Organs handeln, je nach Sichtweise des Trainers.
Als zusätzliche Angabe ist die gesamte Zeit für die Durchführung des Trainings interessant. Für einfache Trainingsmethoden ist die Angabe der Belastungszeit bereits ausreichend zur Beschreibung der Trainingseinheit. Andere Methoden wie Intervallmethoden oder Wiederholungsmethoden erfordern zusätzliche Angaben und die Gesamtzeit setzt sich nur aus der Summe der Teilabschnitte zusammen.
4.2.2 Kategoriespezifische Daten
Abhängig von der Struktur der Trainingseinheit, sprich der Trainingsmethode, wird der Inhalt durch weitere Daten präzisiert.
Ein Intervalltraining besteht z.B. aus einer Aufwärmphase, der Belastungszeit und der Regenerationszeit und der Anzahl der durchzuführenden Intervalle.
Gleichzeitig kann die Schritt- oder Trittfrequenz ein bestimmender Faktor sein. Z.B. unterscheidet sich das Wiederholungstraining mit dem Fahrrad im Bereich Kraftausdauer vom Herz-Kreislauf-Training nur durch den Faktor der Trittfrequenz.
Beim so genannten Wechseltraining werden verschiedene Intensitätsbereiche kombiniert. Daher könnte die Angabe erwünscht sein, in welchem Verhältnis die Intensitätsbereiche verteilt sein sollen.
Hier sind der Phantasie des Trainers keine Grenzen gesetzt. Vor allem eine zukünftige Entwicklung völlig neuer Trainingsmethoden kann eine Vielfalt zusätzlicher Angaben erfordern.
4.2.3 Verbale Ergänzung
Trotz des Versuchs, die Trainingsdaten weitgehend zu standardisieren, bleiben doch immer wieder spezielle Punkte offen, die verbal beschrieben werden müssen.
Zusätzlich kann der Trainer seine Vorstellungen und Gedanken an den Athleten übermitteln, sodass dieser besser versteht, vor welchem Hintergrund die Entscheidungen getroffen wurden.
4.2.4 Erfassung der Trainingsdaten
Die Erfassung der Dokumentations-Trainingsdaten sollte nach Möglichkeit täglich erfolgen. Vor allem ist darauf zu achten, dass alle Daten exakt eingegeben werden. Anders als bei Kontrollwerten hat auch das Nichtvorhandensein von Aufzeichnungen eine Bedeutung.
Als benutzerfreundliche Alternative könnte angeboten werden, dass Trainingseinheiten nicht immer explizit eingetragen werden müssen, sondern nur eine Bestätigung des Planes erfolgt. Diese Methode würde eventuell dazu verleiten, den Plan zu bestätigen, auch wenn dies nicht vollständig der Fall ist.
|
Dat |
RuP |
KG |
ges.KM |
Zeit |
KB |
GA |
EB |
K |
SB |
Wkm |
Platz |
MB |
KaM |
aaA |
Q |
Lauf |
Bem |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabelle 2 Vorschlag für ein Trainingsprotokoll (aus [LIND93], S.83f)
4.3
Kontrollwerte
Der Athlet ist in der Lage, eine gewisse Zahl an Parametern zu ermitteln, ohne technische bzw. medizinische Hilfe in Anspruch zu nehmen. Im Zuge von sportwissenschaftlichen Untersuchungen haben sich einige Parameter herauskristallisiert, die hohe Aussagekraft haben und auf sehr einfache Weise zu ermitteln sind.
4.3.1 Objektive Werte
4.3.1.1 Medizinische Messwerte
Um den körperlichen Zustand des Athleten zu bestimmen, stehen unterschiedliche Messmethoden zur Verfügung. Diese reichen von einfachen Überwachungen, die der Athlet selbst, ohne Messgeräte durchführen kann, bis zu komplexen Laboruntersuchungen.
Aus diesem Grund erscheit es auch logisch, dass unterschiedliche Werte mit unterschiedlicher Häufigkeit aufgenommen werden.
Zu Kategorie jener Messwerte, die vom Athleten ohne Messgeräte aufgenommen werden können, zählen Ruhepuls, Schlafstunden, etc.
In zahlreichen sportwissenschaftlichen Instituten stehen heute bereits kleine Labors zur Verfügung, mit denen eine begrenzte Zahl an Messdaten erfasst werden kann.
Mit höherem zeitlichem und finanziellem Aufwand sind Analysen verbunden, die nur in spezialisierten Labors durchgeführt werden können.
4.3.1.2 Umgebungsbedingungen
Auch Umgebungsbedingungen, die nicht unmittelbar mit dem Training in Verbindung stehen, wie z.B. private Aktivitäten wie Ausgehen, Genuss von Alkohol oder sonstige Fakten, die sich positiv oder negativ auf die sportliche Belastbarkeit auswirken oder die Regeneration beeinflussen (siehe auch 4.5.3), sind in angemessener Weise zu protokollieren.
Bei diesen Daten ist es üblich, nur Abweichungen vom normalen Tagesablauf zu dokumentieren.
4.3.2 Subjektive Werte
Gerade bei subjektiven Werten stellt sich das Problem der einheitlichen und funktionstüchtigen Erfassung. Da Schmerzen in der Muskulatur eben keine messbare Größe darstellen, müssen Methoden gefunden werden, um das Syndrom messbar zu machen. Der Mensch ist auch nicht jeden Tag gleich empfindlich gegenüber bestimmten Reizen.
Näherungsweise wird dieses Problem in der Trainingsanalyse und auch in entsprechenden Analyseprogrammen gelöst, indem die zu erfassende subjektive Empfindung einer Skala zugeordnet wird. Diese Skala wird in der Praxis von Analyseprogrammen oft durch Grafiken veranschaulicht, mit denen sich der Athlet identifizieren kann.
4.3.3 Erfassung
Standardisierte Trainingsprotokolle stellen häufig ein Raster zur Verfügung, in welchen der Athlet oder die messende Person die Daten einträgt. Manchmal erfolgt auch eine Trennung in tägliche Daten und in unregelmäßig erfasste Daten.
Aufgrund der ständigen Weiterentwicklung der Messmethoden, ist darauf zu achten, dass das Protokoll ohne großen Aufwand erweitert werden kann.
Ein Beispiel für ein standardisiertes Protokolls ist in 4.2.4 zu finden. Dort sind die Kontrollwerte „Ruhepuls“ (RuP) und „Körpergewicht“ (KG) in die Tabelle für die Trainingsdokumentation integriert.
4.4
Leistungsdiagnostik
Ziel der Leistungsdiagnostik ist, die aktuelle Leistungsfähigkeit eines Athleten festzustellen. Wenn von Leistungsdiagnostik gesprochen wird sind üblicherweise Belastungstests gemeint, welche in standardisierter Form und unter medizinischer Überwachung durchgeführt werden.
4.4.1 Testmethoden
Aufgrund der ständigen Weiterentwicklung sportwissenschaftlicher Methoden und deren Anpassung an geänderte Verhältnisse unterliegen auch die zugrunde liegenden leistungsdiagnostischen Verfahren einem Wandel. Nicht zuletzt wissenschaftliche Erkenntnisse und neue Werkzeuge der medizinischen Messtechnik ermöglichen immer neue Testmethoden.
Die Anforderungen an die Datenstrukturen, in welche Ergebnisse leistungsdiagnostischer Untersuchungen aufgenommen werden, sind daher vielfältig. Zum einen ist der Standardisierung und der Auswertbarkeit der Ergebnisse Rechnung zu tragen, zum anderen ist maximale Flexibilität zur Definition neuer Testmethoden gefordert.
In den heute üblichen Tests ist meist eine Gemeinsamkeit in der Struktur zu erkennen. Unabhängig davon, welchen Belastungsverlauf sie nehmen, sind sie immer charakterisiert durch die regelmäßige Aufnahme von Messpunkten. Dabei ist nicht klar zu sagen, dass diese Messpunkte unbedingt Zeitintervalle repräsentieren, es können auch Leistungssprünge oder sonstige Einflussgrößen für die Auslösung eines neuen Messpunktes zuständig sein.
Grundsätzlich sind Tests also durch Metadaten über ihre Messpunkte und den dafür gewonnenen Daten charakterisierbar. Meist sind auch noch Umgebungsvariablen wie Lufttemperatur und Luftfeuchtigkeit, Uhrzeit und ähnliche Variablen relevant.
4.4.2 Testbedingungen
Es ist häufig eine begriffliche Unterscheidung von Labortestes und Feldtests zu finden. Während Labortests in einem weitgehend genormten Umfeld stattfinden, sind Feldtests mehr an den realen Wettkampfbedingungen orientiert.
Unterschiede in der Datenerfassung ergeben sich in erste Linie dadurch, dass der Feldtest durch mehr externe Umgebungsbedingungen charakterisiert ist als ein Labortest.
Diese Unterscheidung ist jedoch keine grundsätzliche in der Verarbeitung der Daten, sondern fordert den Trainer, bei der Definition der Tests genügend Variablen zur Feststellung der Parameter zur Verfügung zu stellen.
4.5
Spezielle Einflussfaktoren
4.5.1 Psychische Faktoren
Im Leistungssport ist es nicht ausreichend, nur die physischen Reaktionen zu beobachten, sondern auch emotionale und psychische Faktoren. All dies sind Faktoren, die sehr schwierig formalisierbar sind und daher auch nur schwer erfassbar. Dabei handelt es sich um Attribute wie Motivation, Freude, Verständnis, etc.
Für die Trainingsplanung bedeutet dies, Abwechslung in den Plan zu bringen und Monotonie zu brechen, dem Athleten Ruhetage zum richtigen Zeitpunkt zu gewähren und ihm Zeit für Freizeitaktivitäten einzuräumen.
Angesichts des ohnehin bereits sehr komplexen sportwissenschaftlichen Modells und der schwierigen Messbarkeit des psychologischen Faktors ist eine explizite Betrachtung nicht unbedingt von Erfolg gekrönt.
Trotzdem sollte die Möglichkeit bestehen, diese Informationen zu protokollieren (siehe 4.3.2).
4.5.2 Medikamente
Die Fortschritte in der Medizin bringen auch einen verstärkten Einsatz von Medikamenten mit sich. Der Einfluss auf den menschlichen Körper ist unbestritten und setzt sich meist aus einer gewollten und ungewollten Komponente (Nebeneffekte) zusammen. Der Einfluss auf die sportliche Leistungsfähigkeit bzw. auf den Adaptionsprozess kann sowohl positiv als auch negativ sein. Medikamente, die zur Bekämpfung von Krankheiten eingesetzt werden (z.B. Antibiotika) schwächen den Körper erheblich und dürfen daher auch im Trainingsmanagement nicht unberücksichtigt bleiben.
Eine Grauzone zwischen Ernährung (siehe 4.5.4) und Medikamenten stellen so genannte Nahrungsergänzungsprodukte dar. Diese werden zwar in gleicher Form wie Medikamente eingenommen, sind jedoch von ihrer Funktionsweise der Ernährung zuzuordnen. Der große Unterschied zur normalen Ernährung ist die exakte Dosierung und daher auch Dokumentierbarkeit.
Es sei hier im Besonderen darauf hingewiesen, dass Medikamente im Leistungssport nur innerhalb vorgegebener Rahmen angewandt werden dürfen. Jeglicher über diesen Bereich hinausgehender Einsatz von unerlaubten, leistungssteigernden Mitteln ist nicht Gegenstand dieser Arbeit.
4.5.3 Regenerationsmethoden
Es existieren eine Reihe von Einflussfaktoren, die sich positiv auf die Regeneration und damit auf die Belastungsverträglichkeit auswirken. Da im Hochleistungssport an den Grenzen der Belastbarkeit gearbeitet wird, sind dies wichtige Faktoren, die einen entscheidenden Trainingsvorteil ausmachen.
Im Zusammenhang mit Regeneration ist auch anzumerken, dass Trainingseinheiten nicht unbedingt Belastungen darstellen. Bei Training unterhalb einer gewissen Intensitätsschwelle und Belastungsdauer wird von Kompensationstraining gesprochen. Dieses Kompensationstraining führt nicht zu weiterer Ermüdung des Athleten, sondern hat regenerativen Charakter. Dementsprechend müssen diese Daten im Vergleich zu Belastungseinheiten unterschiedlich gehandhabt werden (siehe 3.4.3).
4.5.4 Ernährung
Einen entscheidenden Einfluss auf die Stoffwechselprozesse im Körper haben die aufgenommenen Lebensmittel. Ihre Zusammensetzung ist sowohl für die Versorgung mit Kraftstoff für den Energiewandlungsprozess als auch für die Versorgung mit Strukturbaustoffen verantwortlich. Zum Beispiel kann Krafttraining seine Wirkung nur unzureichend entfalten, wenn ein Mangel an Proteinen vorherrscht. Andererseits ist bei einem Mangel an Kohlehydraten eine Ausführung von Ausdauertraining nur mit geringerer Leistung möglich oder führt zur Zerstörung von Muskelgewebe. Die Ernährung ist eine sehr komplexe Komponente im Trainingsprozess und wirft sowohl in der Sportwissenschaft als auch in der Medizin noch weitere Fragen auf.
Grundsätzlich sollte es möglich sein, zumindest einige Hauptkomponenten der Nährstoffversorgung in eine Analyse zu integrieren, um ähnlich wie bei den Trainingseinheiten einen Einfluss auf den körperlichen Zustand identifizieren zu können.
Schwierig ist bei der Ernährung auch die Datengewinnung, da die Nahrungsaufnahme nicht so leicht kontrollierbar ist und einen sehr hohen Aufwand des Athleten bedeuten würde. Er müsste jegliche Nährstoffe, die er zu sich nimmt, analysieren und deren Inhaltsstoffe mitprotokollieren.
Auf dem Markt sind einige Softwareprodukte zu finden, die eine Analyse der Ernährung erlauben. Diese beruhen großteils auf Durchschnittsnährwerten gängiger Lebensmittel oder Lebensmittelkombinationen. Auf diese Weise wird die Dateneingabe erleichtert, fordert aber immer noch erhebliche Disziplin und Konsequenz des Betroffenen.
4.6
Herausforderungen in der Datengewinnung
4.6.1 Fehleingaben
Fehleingaben können aus einfachen Unachtsamkeiten resultieren. Beispiele sind fehlende Dezimalstellen, Eingabe in einem falschen Feld, etc. In vielen Fällen können diese Fehler durch Plausibilitätskontrollen eliminiert werden. Dazu kommen Methoden in Frage, die lediglich die Lage im Gültigkeitsbereich prüfen oder durch komplexe Verknüpfung der Eingaben auf Unstimmigkeiten schließen.
Problematischer ist die Eingabe von Trainingsdaten an falschen Tagen. Dem könnte begegnet werden, indem auch trainingsfreie Tage aktiv eingetragen werden und bei der Eingabe von mehreren Einheiten pro Tag nachgefragt wird, ob dies korrekt ist. Auch eine graphische Darstellung sorgt dafür, solche Fehler zu reduzieren. Gleichfalls kann ein Vergleich von Plan und Dokumentation Fehler dieser Art aufzeigen.
Kaum erkennbar hingegen sind Fehler, die aus falscher subjektiver Beurteilung von Tatsachen resultieren oder auch Messfehler mit geringer Abweichung. Bricht ein Messwert zu stark aus dem Trend aus, so kann eine Warnung ausgegeben werden und die Messung wird wiederholt. (Sofern eine Wiederholung der Messung möglich ist.)
4.6.2 Fehlende Werte
Ein Problem, welches sowohl bei der Datengewinnung, als auch bei der Aufbereitung und Analyse zum Tragen kommt, ist jenes der fehlenden Werte („missing values“). Diese stellen eine Inkonsistenz in der Datenbasis dar. Wichtig ist die Unterscheidung zwischen Nullwerten und nicht vorhandenen Werten. Um im Rahmen der Sportwissenschaft ein Beispiel zu suchen, ist es ein gravierender Unterschied, ob ein Messparameter Null ist oder ob dieser nicht gemessen wurde.
Bei Kontrollparametern ist das Problem noch nicht so gravierend, da diese lediglich Zustände abgreifen und interpretieren.
Anders verhält sich die Situation bei Trainingsdaten. Hier steckt die Information nicht nur darin, welche Daten vorhanden sind, sondern auch im Nicht-Vorhandensein von Aufzeichnungen.
Es gilt zu erkennen ob fehlende Werte bedeuten, dass an diesem Tag kein Training durchgeführt wurde, oder ob das Training an diesem Tag nicht aufgezeichnet wurde. In diesem Zusammenhang wird bewusst, welche Bedeutung der ständigen Protokollierung und Instandhaltung der Daten zukommt.
Die Behandlung der fehlenden Werte fällt eher in den Bereich der Datenaufbereitung, wird aber hier im theoretischen Hintergrund diskutiert.
Es gibt einige grundsätzliche Möglichkeiten, fehlende Werte zu behandeln.
Die wohl einfachste ist, sie nicht zu beachten. Je nach Analyseverfahren sind jedoch kontinuierliche Daten erforderlich, um die Auswertung durchführen zu können.
Moderne Statistikpakete stellen Methoden zum Auffüllen fehlender Werte zur Verfügung. So kann ein fehlender Wert entweder durch einen Mittelwert oder Trendwert über die gesamte Zeitreihe ersetzt werden oder durch Interpolation der umliegenden gültigen Messwerte.
Im Einzelfall ist zu entscheiden, ob eine dieser Methoden zulässig ist und die Datenreihe nicht übermäßig verzerrt. Dazu ist Expertenwissen aus Sportwissenschaft und Statistik nötig.
Oftmals sind bessere Ergebnisse zu erreichen, wenn fehlende Werte intuitiv geschätzt werden. Dies ist aber keine wissenschaftlich fundierbare Methode und kann dazu führen, dass die darauf aufbauenden Analysen bewusst oder unbewusst in eine bestimmte Richtung gelenkt werden.
Gerade bei der Messung medizinischer Messwerte sind keine wirklichen Trends zu erkennen. Die Information liegt überdies nicht in der Auswertung der Zeitreihe als solche, sondern vielfach darin, dass überprüft wird ob sich die Messwerte innerhalb der Standardbereiche bewegen.
Dazu kommt die Tatsache, dass Messungen oftmals nur dann erfolgen, wenn mit einer Veränderung eines Wertes gerechnet wird. Aus diesem Grund ist eine Analyse dieser Daten immer auch mit dem Hintergrundwissen des Trainers durchzuführen.
Statistische Methoden stellen meist die Anforderung einer kompletten Messreihe. Ist diese nicht erreichbar, so müssen die Messpunkte in einer Zufallsauswahl gewonnen werden.
Eine reine statistische Auswertung ist daher nicht zulässig und würde zu unbrauchbaren Ergebnissen führen.
5
Wissensmanagement
Im letzten Kapitel wurde beschrieben, wie Daten gewonnen werden können. Um diesen Daten entsprechende Bedeutung zu geben, ist Expertenwissen nötig. Der gezielte Einsatz von Wissen, die Speicherung und die Weitergabe sind Aufgabe des Wissensmanagement.
Neben dem Wissen, welches in den Köpfen der Experten vorhanden ist, existiert dieses auch versteckt in den empirischen Daten.
Letztlich liefert gespeichertes Wissen eine Basis für die zukünftige Entscheidungsfindung. Entsprechende Ansätze werden ebenfalls kurz erläutert, auch wenn diese nicht zum Kernbereich des Wissensmanagement zählen.
5.1
Grundlagen
Der Unterscheidung zwischen Daten, Information und Wissen ist mit der Informationstechnologie und der Diskussion um künstliche Intelligenz eine große Bedeutung zugekommen. Wenn von Wissensmanagement, Expertensystemen und darunter liegenden Datenbanken gesprochen wird, scheint es sinnvoll, dieses Thema im jeweiligen Kontext nochmals zu konkretisieren und eine Abgrenzung der Begriffe vorzunehmen.
Es ist auch eine geschichtliche Entwicklung zu erkennen, die der Informatik aufgrund technischer und methodischer Entwicklungen immer höhere Aufgaben zuteilte und diese von reinen Datenverarbeitungsinstrumenten zu intelligenten, selbständig Informationen produzierenden Systemen erhob.
In den Anfangszeiten lag die Aufgabe von Computern in der Erfassung, Speicherung und Modifikation von Daten. Während in dieser Phase noch keine Semantik in den Daten vorhanden war, sondern diese erst durch die Übersetzung durch Experten hinzugefügt wurde, ist in der nächsten Phase diese Tätigkeit bereits automatisiert.
Dazu gehört die Aufbereitung von Informationen in einer Form, die für den Menschen lesbar und leicht interpretierbar ist. Diese Ära ist geprägt von Begriffen wie Informationsverarbeitung und Informationssysteme. Im Management wird hier von MIS (Management Information System) gesprochen.
Im nächsten Schritt fehlt den Informationen noch die praktische Relevanz. Die gewonnenen Informationen müssen in den entsprechenden Kontext gebracht werden. In diesem Zusammenhang ist das Wissen um sinnvolle Interpretation, Abwägung und Verwendung der Information gemeint (vgl. [WEID91]).
5.1.1 Wissen und Erfahrung
Wissen selbst kann wieder in Tiefenwissen und Oberflächenwissen geteilt werden. Oberflächenwissen bezieht sich mehr auf routinemäßige Entscheidungen, während Tiefenwissen grundlegende Kenntnisse mit einbezieht. Aus Tiefenwissen kann durch intelligente Kombination neues, induktives Wissen generiert werden (vgl. [WEID91])
5.1.2 Expertenwissen und empirisches Wissen
Die Unterscheidung betrifft nicht den Typ des Wissens selbst, sondern vielmehr die Form des Erwerbs von Wissen. Expertenwissen, wie es in Expertensystemen als Basis eingesetzt wird, ist explizites Wissen, welches von Personen formuliert wird. Diese Personen, eben die Experten, haben ihr Wissen im Zuge von Studium von Theorien und praktischen Versuchen erworben und versuchen nun, dieses freizulegen und für die Weiterverarbeitung nutzbar zu machen.
Empirisches Wissen beruht nicht auf Theorien, sondern wird aus empirischen Daten gewonnen. Moderne Methoden aus der Neuro-Fuzzy-Forschung (siehe 7.7) erlauben es, Wissen automatisch aus vorliegenden Daten zu generieren (vgl. [BOT98]).
5.2
Expertensystem
Expertensysteme besitzen die primäre Aufgabe, Expertenwissen zu speichern, zugänglich und verwertbar zu machen. Der Name beruht auf der Idee, durch dieses System gleiche oder bessere Lösungen eines Problems zu erhalten, als durch menschliche Experten (vgl. [KROE94]).
Langjährige Entwicklungen von Expertensystemen und deren Theorie haben große Fortschritte und interessante Anwendungsgebiete aufgezeigt. Gleichzeitig wurden aber auch die Grenzen erreicht, an die der Versuch stößt, Experten durch automatische Systeme zu ersetzen. Heute werden Expertensysteme vorwiegend zur Repräsentation von Wissen und zum Lösen eingeschränkter Entscheidungsprobleme eingesetzt.
In [KROE94] ist eine Darstellung zu finden, in welchen Bereichen Expertensysteme sinnvollen Einsatz finden können und wo eine Implementierung zunehmend schwieriger wird.
So wird je nach Komplexitätsgrad der Probleme eine Kategorie der folgenden Skala zutreffen. Man kann auch davon sprechen, dass die Entscheidungen von der operativen (1) Ebene zu einer immer mehr strategischen (5) Ebene reichen. :
- Prozesse
- Diagnostik
- Überwachung
- Konfiguration und Design
- Planung
Die Kategorie muss noch nicht unbedingt mit der Schwierigkeit des Problems korrespondieren. So können einfache Planungsaufgaben leichter zu lösen sein, als komplexe Überwachungsprobleme. Generell sind jedoch zunehmende Freiheitsgrade ein Maß für die Komplexität.
Da der Prozess ein wohldefiniertes Umfeld und konkrete Bedingungen enthält, in dem nur mehr die Ausführung der Tätigkeit an die Bedingungen angepasst werden muss, ist dieser Bereich für den Einsatz automatischer Systeme hervorragend geeignet, was sich auch in der Praxis in Form von Industrierobotern, automatischen Formularen etc. zeigt.
In der Trainingswissenschaft sind hier Werkzeuge zu verstehen, die Benutzereingaben automatisch zu Trainingsplänen kombinieren und dort alle relevanten Informationen einfügen, die im System vorhanden sind.
Das Diagnostikproblem zielt darauf ab, die Ursache für eine bestimmte erreichte Situation zu identifizieren. Mit Hilfe von Entscheidungsbäumen oder Axiomsystemen können Quellen immer weiter eingegrenzt werden, bis alle bis auf eine oder zumindest wenige Möglichkeiten ausgeschlossen sind.
Eine denkbare Einsatzmöglichkeit wäre, festzustellen, warum ein Athlet eine bestimmte Leistung erbringt oder warum ein Messwert eine bestimmte Größe aufweist. Durch den Vergleich verschiedener Konfigurationen werden Ähnlichkeiten aufgedeckt und mögliche Quellen isoliert.
Die Überwachung oder das Monitoring ist eine Erweiterung der Diagnose um den Faktor der Kontinuität. Dabei werden gewonnene Daten laufend mit Semantik unterlegt. Zum Beispiel kann das Überschreiten eines Grenzwertes bei einer bestimmten Konfiguration Alarmsignale auslösen und entsprechende Lösungsvorschläge bereitstellen.
Der nächste Schritt auf der Komplexitätsskala enthält bereits kreative Komponenten. Es werden nicht nur bestehende Systeme überwacht, sondern Vorschläge für neue Konfigurationen erarbeitet. Ein sehr anschauliches Beispiel ist die automatische Konfiguration von Trainingsplandaten. So könnte vom Trainer ein Gerüst vorgegeben werden und das System hat dann die exakte Ausprägung auf ein optimales Ergebnis abzustimmen.
Beim Begriff Optimierung stößt man bereits auf die ersten Grenzen der Informatik, die bereits im berühmten Optimierungsproblem des „Traveling Salesman“ beschrieben wurden.
Die höchste Kategorie stellt die strategische Planung dar, deren Aufgabe die optimale Ressourcenallokation und die Schaffung optimaler Strukturen darstellt, zur Erreichung eines vorgegebenen Ziels. Offensichtlich sind hierbei sehr rasch die Grenzen der Automatisierung erreicht, da einerseits unzählige Einflussfaktoren zu berücksichtigen sind und andererseits kreative Schaffensprozesse von Bedeutung sind.
Die völlige automatische Erstellung von Trainingsplänen würde ein solches Problem darstellen und nach derzeitigem Stand der Technik wohl über den realistischen Einsatz von Informationstechnik im Trainingsmanagement hinausgehen (vgl. [KROE94]).
5.3
Gewinnung von Wissen
Ein zentrales Problem im Wissensmanagement ist es, Wissen aus den Experten zu gewinnen. In Kapitel 7 wird beschrieben, wie Wissen aus der Analyse vergangener Werte gewonnen werden kann. Dabei handelt es sich um eine indirekte Methode.
Direkte Methoden versuchen, direkt das Tiefenwissen des Experten zu extrahieren. Dazu gibt es Möglichkeiten wie Fragebögen, Mind-Map, Wenn-dann-Regeln, etc.
Grundsätzlich geht es darum, Wissen in wiederverwertbare Daten zu fassen.
5.4
Operationalisierung von Wissen
Nachdem Wissen gewonnen wurde, muss es so umgesetzt werden, dass es dem Trainer im täglichen Bedarf zur Verfügung steht.
Im Folgenden sind einige Verfahren beschrieben, die explizit gespeichertes Wissen in detaillierte Handlungsanweisungen transformieren.
Bei den folgenden Methoden (Entscheidungsbaum oder Entscheidungstabelle) handelt es sich um Möglichkeiten, Wissen und Erfahrung der Akteure in elektronischer Form zu konservieren. Erweitert können diese Systeme durch die Anwendung unscharfer Regelsysteme werden (siehe 7.5).
5.4.1 Entscheidungsbäume
Entscheidungsbäume sind relativ einfache Strukturen, um systematisch einer optimalen Entscheidung zu gelangen. Sie finden täglich Einsatz in vielen Bereichen den Managements, explizit oder noch öfter implizit.
Der Aufbau von Entscheidungsbäumen gleicht einem Ablaufdiagramm, dem der Entscheidungsträger folgt, indem er eine Frage nach der anderen beantwortet und auf Basis des letzten Ergebnisses immer weiter ins Detail der Materie vordringt.
Implizit findet diese Methode weit verbreitete Anwendung in der Trainingsplanung.
Ein Beispiel eines Entscheidungsbaumes im Leistungstraining:
Fragestellung: „Welches Trainingsprogramm soll nächste Woche durchgeführt werden?“
Durch die sequentielle Beantwortung der folgenden Fragen kommt der Trainer zu einem Ergebnis. In diesem Beispiel wird ein sehr stark vereinfachter Entscheidungsprozess verbal dargestellt.
- „In welcher Phase befindet sich der Athlet?“
a. Vorbereitung: weiter bei 2
b. Wettkampf: weiter bei 10
c. Regeneration: weiter bei 20
- „Ist die Grundlagenausdauer genügend ausgebildet?“
a. Ja: weiter bei 3
b. Nein: weiter bei 4
- „Wie ist der aktuelle Zustand?“
a.
erholt: Plan: Grundlagenausdauer: 3 Stunden
b. müde: Plan: Regeneration: 1 Stunde
In der Praxis ist
dieser Prozess komplexer und läuft meist intuitiv ab. Aufgrund der sehr großen
Zahl an Verzweigungen (Entscheidungen) wird eine graphische Darstellung sehr
schnell unübersichtlich. Die Komplexität des Baumes wächst mit der Tiefe
exponentiell an. In Abbildung
6 ist nur ein durchgängiger Entscheidungspfad dargestellt.
Abbildung 6 Entscheidungsbaum dargestellt als Ablaufdiagramm
5.4.2 Entscheidungstabellen
Entscheidungstabellen stellen operative Vorschriften für die Behandlung von Standardsituationen dar. Sie werden meist aus verbaler Formulierung von Expertenwissen generiert.
Grundbausteine sind Bedingungen und Aktionen. Jeder Kombination von Bedingungen sind eine oder mehrere Aktionen zugeordnet. Dadurch können in Standardsituationen völlig automatisch Entscheidungen getroffen werden.
Wie in Tabelle 3 dargestellt, werden Parameter und Handlungsanweisungen kompakter dargestellt, als in einem Entscheidungsbaum. Der im Entscheidungsbaum ausgeführte Pfad ist grau gekennzeichnet.
|
Entscheidungsparameter |
||||||||||||
|
Phase? |
1 |
2 |
3 |
1 |
2 |
3 |
1 |
2 |
3 |
1 |
2 |
3 |
|
Ausdauer? |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
|
erholt? |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
Aktion (Trainingszeit in Stunden) |
||||||||||||
|
GA1 |
|
|
|
|
|
|
3 |
|
|
|
|
|
|
Reg |
|
1 |
1 |
1 |
|
1 |
|
|
|
|
|
|
Tabelle 3 Entscheidungstabelle
Die Entscheidungstabelle kann durch Zusammenfassen von Parameter-Tuppeln mit gleichen Aktionen vereinfacht werden, analog zur Optimierung von digitalen Schaltkreisen. Beispielsweise könnte, vereinfacht dargestellt, Regenerationstraining (Reg) immer nötig sein, wenn der Athlet nicht erholt ist, unabhängig von den anderen Parametern. Ist diese Optimierung bekannt, kann auf die Überprüfung der übrigen Parameter verzichtet werden.
6
Modelltheorie und Modellanwendung
Nachdem in Kapitel 2 bereits sportwissenschaftliche Modelle zur Sprache kamen, wird in diesem Abschnitt auf zugrunde liegende Theorien der Modellbildung und der Simulation eingegangen.
Im Weiteren wird auf die Anwendung dieser Theorien in bestimmten Teilbereichen der Sportwissenschaften bzw. im Trainingsmanagement eingegangen. Im Zuge dessen werden auch bestimmte grundsätzliche Anforderungen und Probleme diskutiert.
Einzelne Methoden zur Modellbildung, Datengewinnung, Datenaufbereitung und Datenanalyse bilden den Inhalt des Kapitels 7.
6.1
Grundlagen der Modellbildung
6.1.1 Der Modellbegriff
Ziel der Modellbildung im Sport ist es, Informationen zu isolieren, die ansonsten nicht direkt zugänglich sind. Ein Modell stellt per Definition ein Abbild eines Ausschnittes der Wirklichkeit dar, zu dem eine unidirektionale, relationale Abhängigkeit besteht. Jeder Vorgang, der in der Realität zu einer Reaktion führt, führt auch im Modell zur korrespondierenden Reaktion. Realität und Modell existieren unabhängig voneinander. Das bedeutet, dass ein Sachverhalt, der im Modell beobachtet wird, in der zugeordneten Realität auch ohne dieses Modell existiert (vgl. [MÖLL92], [WILB96]).
Der Grund für die Anwendung von Modellen in der im Bereich der Sportwissenschaften liegt darin, dass es nicht möglich ist, die Belastungsgrenze jedes Athleten auszuprobieren. Viel eher soll versucht werden, aus allgemeinen empirischen Daten, sowie spezifischer Informationen über den Athleten aus der Vergangenheit und Gegenwart, auf diese Grenzen zu schließen.
6.1.1.1 Modellarten
Bevor weiter in Details Modellbildung vorgedrungen wird, soll vorab geklärt werden, welche Charakteristika und Aufgaben Modellen zugeschrieben werden.
[WILB96] klassifiziert Modelle in vier Typen:
Beschreibungsmodelle dienen nur dazu, existierende Fakten zu beschreiben, ohne auf interne Prozesse Rücksicht zu nehmen.
Erklärungsmodelle haben dagegen die Aufgabe, Ursache-Wirkungs-Beziehungen zu erklären. Diese Modelle sind daher um die Möglichkeit von Schlussfolgerungsprozessen erweitert. Aufbauend auf einer Regelbasis können sie Grundlage von Expertensystemen sein.
Weitere Typen sind Prognosemodelle und Entscheidungsmodelle. Vielfach bauen diese auf Erklärungsmodellen auf. Einem Prognosemodell muss jedoch nicht zwingend ein Erklärungsmodell zugrunde liegen. Speziell beim Einsatz neuronaler Netze ist dies nicht gegeben und trotzdem können durch Modellierung aus Vergangenheitsdaten brauchbare Prognosen gewonnen werden. (vgl. [WILB96]).
6.1.1.2 Homomorphie und Isomorphie
Ziel eines Modells ist es, die Realität strukturgleich nachzubilden. Aus der Algebra wurden die Begriffe Homomorphie und Isomorphie übernommen. Isomorphie ist die stärkste Bedingung für die Zuordnung von Modell und Realität. Die Elemente des Modells besitzen zu den Elementen der Realität eine bijektive Beziehung. In empirischen Modellen (z.B. Wirtschaftswissenschaften, Medizin, etc.) ist eine solche eindeutige Zuordnung nur in Ausnahmefällen möglich. In den weitaus meisten Fällen kann nur eine homomorphe Abbildung gefordert werden. Diese setzt nur eine surjektive Beziehung voraus, welche die Elemente der Realität auf die des Modells abbildet, aber nicht umgekehrt (vlg. [WILB96]).
Nach Art der Abbildung wird in strukturhomomorphe und verhaltenshomomorphe Modelle unterschieden.
Die wesentlichste Forderung für Prognose- und Entscheidungsmodelle ist die Homomorphie des Verhaltens. Das Modell muss auf gleiche Eingabegrößen gleich reagieren wie das reale System. Der Aufbau des Modells ist jedoch nicht entscheidend, sondern es wird im Simulationsprozess als Blackbox betrachtet.
Im Gegensatz dazu wird bei der Homomorphie der Struktur gefordert, dass alle Elemente eines Modells einem oder mehreren Elementen der Realität entsprechen. Diese Forderung ist vor allem dann von Bedeutung, wenn nicht nur das Ergebnis eines Simulationsprozesses interessiert, sondern auch die internen Zustände, die ein System auf diesem Weg durchläuft. (vgl. [WILB96]).
Abbildung 7 Arten der Homomorphie
6.1.2 Abstraktionsebenen
In [MÖLL92] wird im Zuge der Modellbildung von verschiedenen semantischen Stufen gesprochen.
Als Stufe 0 wird jene der Reize, Eindrücke und Vorstellungen verstanden. Sie führt zur internen Modellbildung, in der nur Daten gesammelt werden, wodurch sich implizit durch die Zusammenhänge ein Modell ergibt, welches aber noch nicht in diesem Sinne identifiziert ist.
In weiterer Folge werden auf Stufe 1 Assoziationen zwischen den gewonnenen Daten hergestellt und Interdependenzen aufgedeckt. Um nun ein Modell zu verallgemeinern und wissenschaftlich verwertbar zu machen, folgen in den weiteren Stufen die Kommunikation der gewonnenen Erkenntnisse und eine zunehmende Formalisierung.
Es ist zu erkennen, dass mit jeder Stufe eine konkretere Darstellung der gewonnenen Erkenntnisse einhergeht. Gleichzeitig ist aber auch durch die Generalisierung ein Informationsverlust zu verzeichnen, da eine große Menge von Informationen auf ein begrenztes System von Regeln oder Fakten reduziert wurde.
Der Vorteil der Abstraktion besteht nun offenbar darin, dass aus den generalisierten Regeln neue Erkenntnisse abgeleitet werden können.
Durch einen ständigen Abgleich der neu aus dem System abgeleiteten Erkenntnisse mit den tatsächlich gewonnenen Daten entsteht ein Rückkopplungsprozess, der zu einer inkrementellen Verbesserung des Modell führen soll.
So zeichnen sich die Schritte der Modellbildung direkt ab. Im ersten Schritt, welcher in der Literatur häufig als Qualifikation bezeichnet wird, werden Erkenntnisse aus dem realen System in ein abstraktes Modell gefasst.
Das gewonnene abstrakte Modell wird implementiert und in ein reales Modell überführt. Das kann z.B. durch Programmierung, Erstellung einer Regelbasis, physikalische Nachbildung oder unter Zuhilfenahme ähnlicher Methoden geschehen. Dieser Schritt wird oft als Verifikation oder auch als Rektifikation bezeichnet. Der Begriff Verifikation ist insofern begründet, als in diesem Schritt auch eine Überprüfung des Modells mit vorliegenden Beispieldaten vorgenommen werden kann und damit eine Validation bzw. eine Falsifizierung möglich wird. Im Zuge der Verifikation kann neben einfachen Soll-Ist-Vergleichen auch weiteres deklaratives Wissen eingebracht werden.
Ist das Modell hinreichend verifiziert, schließt sich der Kreislauf insofern, als die Simulation eine Vorhersage der Zustände des realen Systems erlaubt, was die eigentliche Motivation der Modellbildung darstellt.
6.1.3 Allgemeine Methoden der Modellbildung
In der Praxis finden heute zwei grundsätzlich unterschiedliche Methoden der Modellbildung Anwendung. Die deduktive oder die empirische Methode. Ausgangspunkt jeder Modellbildungsmethode ist üblicherweise eine vorliegende Datenbasis, auf Basis derer Zusammenhänge identifiziert werden sollen, um so die Simulation zu ermöglichen.
6.1.3.1 Deduktive Modellbildung
Bei der deduktiven Methode werden aus den gewonnenen Daten Ähnlichkeiten, Abhängigkeiten, statistische Zusammenhänge, etc. erkannt. Davon ausgehend wird nun versucht, eine qualitative Vorstellung des funktionalen und dynamischen Verhaltens des Systems zu gewinnen.
Dies ist bei relativ einfachen, technischen Systemen und vor allem solchen, bei denen nahezu alle Einflussfaktoren bekannt sind, relativ leicht möglich. Probleme treten auf, wenn nicht alle Parameter bekannt sind, speziell bei komplexen, dynamischen, nichtlinearen Systemen. Medizin und Sportwissenschaft sind neben soziologischen oder wirtschaftswissenschaftlichen Disziplinen Paradebeispiele für solche Systeme.
Je komplexer ein System ist, desto wichtiger erscheint die experimentelle Überprüfung der Simulationsergebnisse. Zu bedenken ist in diesem Zusammenhang die vielfach beschriebene Tatsache, dass keine absolute Verifikation möglich ist, sondern lediglich eine Falsifizierung. Für praktische Anwendungen kann jedoch, bei Beschränkung oder Vorselektion der Eingangsdaten, eine hinreichende Genauigkeit und Zuverlässigkeit erzielt werden. Das Vertrauen in das System steigt, je mehr Eingansdatensätze korrekte Ergebnisse liefern (vgl. [MÖLL92]).
6.1.3.2 Empirische Modellbildung
Der zweite Ansatz geht davon aus, dass bestimmte Informationen über das reale System bekannt sind. Aufgrund dieser Informationen über mathematische Gleichungsklassen wird ein so genannter Systemtyp festgelegt. Die Überprüfung der Ergebnisse führt über eine abgeleitete Fehlerfunktion zur Korrektur der Parameter des Modells. Problematisch ist, dass bei medizinischen Systemen nur selten Reaktionsfunktionen bekannt sind und oft relativ große Messfehler zu beobachten sind. Der Einfluss der Messfehler oder Messungenauigkeiten auf die Fehlerfunktion ist nur schwer abzuschätzen (vgl. [MÖLL92]).
6.1.4 Testsignale für die Verifikation
Für die Verifikation eines technischen Modells werden üblicherweise Testsignale angelegt und die Reaktion mit dem realen System verglichen. Dies ist bei nicht-technischen Systemen nur bedingt möglich, da die Stimulation mit dem Testsignal in der Realität nicht realisierbar ist. Außerdem können soziale Systeme oder auch organische Systeme nur sehr schwer oder nur mit sehr hohem Aufwand in einen gewünschten Zustand gebracht werden, um den Test durchzuführen.
Eine Verifikation ist daher nicht direkt durch Versuche möglich, sondern nur im langfristigen Einsatz des Modells. Die Validierungsdaten sind in der Regel nur in einem Standardbereich vorhanden. Ob das Modell auch in Extremsituationen richtige Ergebnisse liefert, ist schwer zu belegen (vgl. [MÖLL92]).
6.2
Aufgaben von Modellen im Trainingsmanagement
Bevor auf einzelne Methoden der Datenanalyse und der Modellbildung eingegangen wird, werden in diesem Abschnitt kurz die generellen Ziele dieser Methoden erklärt.
6.2.1 Klassifikation
In einem breiten Bestand von Daten kann das Auffinden von Clustern Auskunft über interessante Zusammenhänge geben. Als Cluster werden Gruppen von Daten bezeichnet, die innerhalb des Clusters große Ähnlichkeiten und im Vergleich zu anderen Gruppen große Unterschiede aufweisen. Die Klassifikation findet im Sport zahlreiche Anwendungen.
Vor allem im Nachwuchsbereich ist es eine langjährige, nicht unumstrittene Tradition, junge Athleten entsprechend bestimmter Kriterien in Klassen nach ihrer Tauglichkeit für bestimmte Sportarten einzuteilen. Vor allem im ehemaligen Ostblock wurden diese Methoden professionell betrieben und die Athleten nach einer Vielzahl von Parametern eingeteilt und so die Zukunft vorgeplant. In dieser Vorgehensweise ist auch die grundsätzliche Problematik der Klassifikation von Menschen zu erkennen. Vielfach wurden die Ergebnisse überinterpretiert und als alleinige Entscheidungsbasis verwendet. Durchaus sinnvoll können diese Methoden jedoch sein, um dem Athleten eine Entscheidungshilfe zu geben und ihn auf seine Stärken und Schwächen hinzuweisen.
In Abbildung 8 wird ein fiktives Ergebnis einer Clusteranalyse dargestellt. In dieser fiktiven Untersuchung wurden erfolgreiche Athleten aus Kraft- und Ausdauersportarten auf die Faktoren Maximalkraft und maximale Sauerstoffaufnahme (VO2max) untersucht.
Es können offensichtlich zwei Cluster (A und B) identifiziert werden. Da nun die Existenz der Cluster gezeigt wurde, gilt es festzustellen, ob die Clusterzugehörigkeit auf die ausgeübte Sportart schließen lässt. Ist ein statistisch signifikanter Überhang von Kraftsportlern in Cluster A und Ausdauersportlern in Cluster B zu finden, so kann darauf geschlossen werden, dass die gemessenen Faktoren Einfluss auf den Erfolg in der jeweiligen Sportart ausüben.
Abbildung 8 Schema einer Clusteranalyse Ausdauer und Kraft
Ein weiterer Ansatz zu dieser Methode ist in der Klassifizierung von Sportarten zu sehen. So können Ähnlichkeiten in den Anforderungen verschiedener Sportarten identifiziert werden und gegebenenfalls Erkenntnisse aus mehreren Sportarten zu einer gemeinsamen Datenbasis verknüpft werden. Diese Vorgehensweise wird schwierig, wenn die Daten in unterschiedlicher Form gespeichert werden, daher sollte es Aufgabe der Informatik, bzw. eines Informationssystems sein, für eine standardisierte und trotzdem flexible Aufzeichnung der Daten zu sorgen.
Klassifiziert können auch Trainingseinheiten und Trainingsmethoden nach ihrer Wirkung auf den Körper werden. Durch die Klassifizierung der Trainingsmethoden über die medizinischen Messwerte können eventuell vorhandene ähnliche Wirkungen aufgedeckt werden.
6.2.2 Parameterschätzung
Dieser Begriff entspringt der Wissenschaft der induktiven Statistik. Gemeint ist dort die Identifikation von Beschreibungsparametern einer bekannten Datenmenge. Eine der verbreitetsten Methoden ist die Punkt- und Intervallschätzung basierend auf z.B. einer Normalverteilung. Diese relativ einfachen statistischen Methoden stellen ein sehr eingeschränktes Modell zur Verfügung, welches jedoch für bestimmte Anwendungsbereiche sinnvolle Ergebnisse liefern kann.
Eine begriffliche Erweiterung stellt die Schätzung von Modellparametern dar. Werden Daten basierend auf einem bestehenden Modell analysiert, kann versucht werden, die Prämissen dieses Modells zu schätzen und so die Parameter für zukünftige Simulationsanwendungen nutzen.
In der Praxis werden diese Grenzwerte intuitiv durch Beobachtung vergangener Werte geschätzt. Dies könnte einen Ansatzpunkt für informationstechnische Analyse und eine empirisch begründete Schätzung dieser Parameter darstellen.
Einfache Modelle sind in der Sportwissenschaft vorhanden, die nur zu Warnungen führen, wenn ein bestimmter Kontrollwert überschritten wird. Beispielsweise wird der Ruhepuls täglich gemessen. Wenn der Wert 10 % über dem Durchschnitt liegt, so kann dies als Zeichen interpretiert werden, dass der Körper nicht im Gleichgewicht ist.
6.2.3 Ursachenerklärung
Eines der zentralen Probleme in jedem Managementprozess ist es, Ursachen zu identifizieren, die zu einer bestimmten gewünschten oder unerwünschten Situation geführt haben. So könnte von Interesse sein, welche Trainingsformen oder externe Einflüsse einer positiven oder negativen Leistungsentwicklung vorausgingen. Dies ist wichtig, um für spätere Entscheidungen Erfahrungen zu sammeln.
Die große Herausforderung bei dieser Aufgabe besteht vor allem darin, dass die Faktoren zu identifizieren sind, die tatsächlich für die Reaktion verantwortlich sind. In technischen Systemen ist dies durch Versuche mit fest vorgegebenen Parametern relativ leicht möglich. Anders verhält sich die Situation in nicht oder schwach deterministischen Systemen, die von einer Vielzahl von Variablen beeinflusst werden. So ist es in der Sozialwissenschaft ebenso wie in der Ökologie und Biochemie schwierig, den aktuellen Zustand, d.h. die Ausgangskonfiguration für einen Versuch zu erkennen. Oftmals sind diese Variablen nicht messbar oder es ist überhaupt nicht bekannt, welche Variablen existieren.
Die Identifikation der Versuchsprämissen ist jedoch nicht die einzige Grenze, auf die man bei komplexen Modellen stößt. Bei volkswirtschaftlichen Modellen sind Versuche offensichtlich nicht möglich. Das trifft auch teilweise auf die Trainingswissenschaft zu.
Es ist wohl schwer vertretbar, Athleten für Versuche zu verwenden. Speziell im Spitzensport ist es kaum möglich, einen Athleten dafür zu gewinnen, etwas völlig neues auszuprobieren und entsprechende Risiken einzugehen.
Das bedeutet, dass für die Erklärung der Wirkung nur Vergangenheitswerte zur Verfügung stehen, deren Bedingungen oft nur unzureichend dokumentiert werden konnten.
Im Zuge von Labortests wird versucht, diese Bedingungen soweit wie möglich zu standardisieren, um tatsächlich von den dort gewonnenen Messwerten auf den Leistungszustand zurückschließen zu können.
6.2.4 Abhängigkeiten
Das Auffinden von Abhängigkeiten ist in mehrerer Hinsicht interessant für die Trainingswissenschaft. Zum einen sollen dadurch messbare Indikatoren identifiziert werden, die auf den nicht messbaren körperlichen Zustand hindeuten. Dies wäre zum Beispiel die Relevanz von leistungsdiagnostischen Tests auf die tatsächlichen Wettkampfergebnisse oder auch das Ergebnis von Blutwerten auf die getestete Leistungsfähigkeit.
Zum anderen sind eventuelle Interdependenzen zwischen unabhängig geglaubten Variablen auffindbar. So könnte zum Beispiel erkannt werden, dass ein Zunehmen der Leistungskomponente „Kraft“ tendenziell zu einer Reduktion der Leistungskomponente „Ausdauer“ führt. (siehe 2.2) Wichtig ist auch in diesem Zusammenhang zu erwähnen, dass Abhängigkeiten vielfach nur unter bestimmten Voraussetzungen existieren. Der eben angesprochene negative Effekt ist nur dann zu verzeichnen, wenn ein bestimmtes Trainingsniveau überschritten ist und eine beidseitige Weiterentwicklung nicht mehr möglich ist. Diese Zusammenhänge belegen empirisch die Notwendigkeit für Spezialisierung im Spitzensport.
6.2.5 Entwicklungsprognosen
Bei medizinischen und sportwissenschaftlichen Problemstellungen ist es nicht oder nur mit großem Aufwand möglich, praktische Versuche durchzuführen. (siehe 6.1) Die Tragweite solcher Versuche erstreckt sich in finanzielle aber auch ethische Grenzbereiche.
Das Modell dient daher auch dazu, zukünftige Entwicklungen zu prognostizieren. Ist ein Modell ausreichend genau, kann z.B. darauf geschlossen werden, welche Leistungsfähigkeit ein Athlet bei Durchführung eines bestimmten Trainingsprogramms erreicht. Gleichfalls interessant ist die Tatsache, ob ein Athlet durch das geplante Training in körperlich instabile Zustände geraten könnte oder ob er noch große Reserven hätte.
Eine völlig andere Aufgabe kommt der Prognose bei der Selektion von Athleten zu. Aufgrund von empirischen Daten soll auf die Eignung für gewisse Sportarten oder die generellen athletischen Entwicklungsmöglichkeiten geschlossen werden. Auf Basis dieser Ergebnisse können frühzeitig nötige Maßnahmen zur Spezialisierung getroffen werden (siehe 6.2.1) (vgl. [LINDER93]).
6.2.6 Optimierung
Das Ergebnis eines Entscheidungsprozesses sollte zu einer optimalen Ressourcenplanung führen, um das Ziel zu erreichen.
In Kapitel 5.2 wurde Optimierung als Grenzbereich der Informatik dargestellt. Mit konventionellen Methoden müssen alle möglichen Konfigurationen getestet werden, um das optimale Ausgangsergebnis zu identifizieren. Sind viele Variablen zu berücksichtigen, so wird diese Aufgabe immer schwieriger. Um den Aufwand zu begrenzen, ist es sinnvoll, eine Vorauswahl zu treffen und den Lösungsraum auf vernünftige Ergebnisse zu begrenzen.
Neuere Ansätze zur Lösung von Optimierungsproblemen sind genetische Algorithmen (siehe 7.4).
6.3
Anforderungen an sportwissenschaftliche Modelle
An Modelle zur Repräsentation medizinischer oder auch sportlicher Reaktionsmuster sind spezielle Anforderungen zu stellen. Einige Punkte machen die Modellierung natürlicher Organismen komplexer als jene von technischen Objekten. Die Zusammenhänge sind vielfach hochgradig nicht-deterministisch und es muss davon ausgegangen werden, dass nur ein geringer Teil der Parameter tatsächlich erklärt werden kann.
6.3.1 Komplexität
Sportwissenschaftliche Modelle sind geprägt von einer großen Zahl an Variablen und von ausgeprägter Nichtlinearität. Zwischen den Variablen bestehen nicht transparente Wechselwirkungen, die auch wissenschaftlich nicht immer eindeutig begründet werden können. Unbekannte Einflussfaktoren müssen identifiziert und gefiltert werden, um die Wirkung der bekannten Faktoren abzuschätzen.
6.3.2 Dynamik und Anpassungen
Der menschliche Körper, hinsichtlich seiner Leistungsfähigkeit betrachtet, ist ein zyklisch, dynamisches System hoher Komplexität. Da das Ziel des Trainings die Anpassung an die neuen Gegebenheiten ist und damit immer eine Veränderung des Originalobjektes einhergeht ist es nötig, auch die Reaktionen des Modells entsprechend den Veränderungen anzupassen.
Im Detail heißt dies, dass mit der Wirkung des Trainings eine bisher als gültig angesehene Reaktion nicht mehr in diesem Ausmaß stattfindet.
Die Dynamik besteht aus mehreren Komponenten. Zum einen sollte eine langfristige positive Tendenz vorhanden sein, die der Karriereentwicklung entspricht.
Überlagert sind zyklische Veränderungen, die sich im Laufe von einem Jahr (Saisonplanung), eines Monats oder Mesozyklus, einer Woche (Wettkämpfe am Wochenende) oder eines Tages (Schlaf-/Wachrhythmus) wiederholen (siehe 3.4).
6.3.3 Modelle zur Entscheidungsunterstützung
Im Trainingsmanagementprozess dienen Modelle letztlich als Basis für Entscheidungen. Aus dieser Sicht werden an die Modelle spezielle Anforderungen gestellt (vgl. [WILB96]).
Entscheidungsprozesse sind oft mit Unsicherheit und Risiko verbunden. Das Risiko, welches aus falschen Entscheidungen resultiert, basiert auf Unwissenheit über die zu erwartende Entwicklung. In [WILB96] werden zur Unsicherheit die folgenden Punkte aufgezählt:
- Datenunsicherheit (sind Daten für den Problembereich geeignet? Trainingsdaten, Messwerte, etc.),
- Zielunsicherheit (ist das Lösungsmodell für die Zielsetzung geeignet? Langfristige Trainingsplanung, Zustandsidentifikation, Leistungsprognose, etc.) und
- Methodenunsicherheit (kann mit den Methoden eine geeignete Lösung gefunden werden?).
Des Weiteren sind Entscheidungsmodelle von Unschärfen geprägt. Durch die Mensch-Maschine-Kommunikation müssen „linguistische und unscharfe Variablen“ („hoch“, „niedrig“, etc.) in elektronisch verarbeitbare Variablen transformiert werden. Dies kann z.B. mit Hilfe von Fuzzy-Methoden erreicht werden (siehe 7.5.3).
Dem Problem der Unvollständigkeit kommt ein besonderer Stellenwert zu, da z.B. nicht eingetragene Trainingseinheiten oder Messwerte nicht einfach ignoriert werden können (siehe 4.6.2). In Expertensystemen werden unvollständige Informationen mit Defaults ersetzt oder Methoden „nichtmonotoner Logik“ oder „nichtmonotonen Schließens“ eingesetzt (vgl. [WILB96]).
7
Methoden zur Analyse und Modellbildung
Im letzten Kapitel wurde erörtert, welche Aufgaben einem Modell in der Trainingswissenschaft zukommen und welche Eigenschaften es erfüllen muss. In diesem Kapitel werden Möglichkeiten der Modellbildung diskutiert und die unterschiedlichen Ansätze mit ihren Vor- und Nachteilen beleuchtet.
7.1
Data-Mining und KDD
7.1.1 Grundlagen
Die Begriffe Data-Mining und Knowledge Discovery in Databases werden in der wirtschaftswissenschaftlichen Literatur äquivalent verwendet und wie folgt definiert:
„Data
Mining finds novel, valid, potentially useful and ultimately understanding
patterns in mountains of data.“ (Gregory Piatetsky-Shapiro, aus [WIED01],
S.19)
“KDD bzw.
Data-Mining beschreibt automatisierte Verfahren, mit denen Regelmäßigkeiten in
Mengen von Datensätzen und in eine für Nutzende verständliche Form gebracht
werden.“ (Reginald Ferber, aus [WIED01], S.19)
Der erweiterte
Data-Mining-Begriff umfasst auch die entsprechenden Lösungsansätze und Methoden. Dies sind sowohl konventionelle
statistische Methoden, als auch neue Ansätze aus der künstlichen Intelligenz.
Eine Abgrenzung wird in „niedrige“ und „höhere“ Analyseverfahren vorgenommen.
Während „niedrige“ Methoden der manuellen Aufbereitung von Daten (z.B.
SQL-Statements) oder der Überprüfung bestehender Hypothesen dienen, können
„höhere“ Methoden automatisch unbekannte Hypothesen auffinden (vgl. [KRAH98]).
Die Anwendungsbereiche des Data-Mining wurden in den letzten Jahren aufgrund technologischer Entwicklungen (Datenbanken, Rechnerleistungen, Neuronale Netzte, Fuzzy-Methoden, Statistik, etc.) und den Anforderungen eines kompetitiven Marktes immer vielfältiger (vgl. [WIED01]).
Im Folgenden wird der Data-Mining-Prozess mit seinen Anwendungsbereichen in der Sportwissenschaft dargestellt.
7.1.2 Data-Mining-Prozess
Ausgangspunkt des Prozesses ist immer ein Objekt, das beschrieben werden soll. Dies wird im allgemeinen Fall der Athlet sein, mit seinen Eigenschaften wie Leistungsfähigkeit, Reaktion auf Trainingsreize, Erholungsfähigkeit, etc. Als Objekt kann allerdings auch eine Trainingseinheit, eine Trainingsmethode oder ein anderes Element der Trainingswissenschaft dienen.
Mit dem Objekt verbunden ist die Problemdefinition. Welche Frage soll beantwortet werden und sind die nötigen Daten vorhanden, um diese Frage zu beantworten?
Die Datenbasis ist so zu wählen, dass sie möglichst exakt die dem Untersuchungsziel entsprechenden Informationen enthält. Wenn die Daten fehlende Werte oder Ausreißer enthalten, sind diese aufzubereiten. Dieses Problem liegt im Trainingsmanagement sehr intensiv vor, wie in 4.6 gezeigt wurde.
Im Falle von hochdimensionalen Datenbasen kann eine Datenreduktion sinnvoll sein, sofern nur geringe Informationsverluste damit verbunden sind (z.B. kann bei Wiederholungstrainingsmethoden nur die Belastungssumme, ohne Aufteilung der Belastungen, interessant sein).
Nun kann mit der eigentlichen Auswertung begonnen werden. Für die Untersuchung des Objektes im nächsten Schritt stehen zwei grundsätzliche Ansätze zur Verfügung.
Mit Hilfe der Interdependenzanalyse werden Objekte mit ähnlichen Ausprägungen zu Gruppen zusammengefasst. Es können z.B. Athleten nach ihren Leistungseigenschaften klassifiziert werden, verschiedene Trainingsformen nach ihrer Wirkung auf den Körper, etc.
Im Gegensatz dazu dient die Dependenzanalyse dazu, Abhängigkeiten zwischen Eigenschaften des Objektes zu identifizieren. Als Beispiel kann für das Objekt „Athlet“ der Einfluss eines medizinischen Messwertes auf die Regenerationsfähigkeit genannt werden oder die Wirkung einer bestimmten Trainingsmethode auf gegebene Messwerte.
Für die Phase der Auswertung können unabhängig vom gesamten Data-Mining-Prozess verschiedenste Methoden Anwendung finden. Die Spannweite reicht von klassischen statistischen Methoden bis zu Methoden der künstlichen Intelligenz (vgl. [WIED01]).
Die in diesem Prozess gewonnenen Daten und Zusammenhänge müssen nun vor dem wissenschaftlichen Hintergrund interpretiert werden, sodass die ursprüngliche Fragestellung beantwortet werden kann.
Im Zuge der Interpretation können neue Fragen auftauchen, die ein nochmaliges Durchlaufen des Prozesses mit anderen Parametern oder Daten erfordern.
Abschließend sind die gewonnenen Informationen so aufzubereiten, dass sie für alle Betroffenen, d.h. Athleten, Trainer, Mediziner, etc. verständlich sind. In diesem Vorgang ist meist eine Visualisierung sinnvoll (vgl. [WIED01]).
Der Data-Mining Prozess ist also ein übergeordneter Prozess, welcher sich der in den folgenden Abschnitten beschriebenen Methoden bedient.
7.2
Klassische Statistik
Die Statistik stellt exakte Methoden zur Verfügung, um Zusammenhänge, Klassenzugehörigkeit und Prognosewerte abzuschätzen. Vorteil klassischer statistischer Methoden ist ihre mathematisch unumstrittene Basis (im Gegensatz zu Methoden der Künstlichen Intelligenz, siehe 7.6).
Speziell in relativ einfachen Modellen, in denen lineare Abhängigkeiten existieren, ist die lineare Regressionsanalyse seit langem die Methode erster Wahl.
Der Einsatz dieser und verwandter Methoden setzt ein Vorhandensein von Wissen und Hypothesen über Zusammenhänge zwischen genau bestimmten Eingangs- und Ausgangsvariablen voraus.
7.2.1 Methoden klassischer Statistik
7.2.1.1 Korrelationsanalyse
Durch Korrelationsanalyse können direkte Interdependenzen zwischen Variablen aufgefunden werden. Basis für die Berechnung ist die Kovarianz. Diese prüft die Abweichung zweier Variablen gegenüber dem jeweiligen Mittelwert. Ist die Abweichung in den meisten Fällen in die gleiche Richtung gegeben, so wird auf einen positiven Zusammenhang geschlossen, im gegenteiligen Fall auf einen negativen Zusammenhang. Wird keine eindeutige Tendenz erkannt, kann angenommen werden, dass die Variablen unabhängig sind (vgl. [ECK02]).
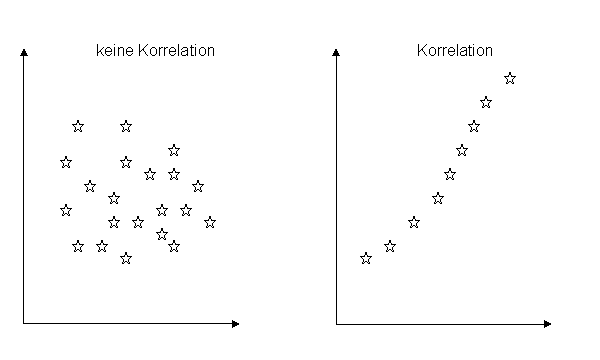
Abbildung 9 Punktverteilung bei vorhandener bzw. nicht vorhandener Korrelation
Ein Ziel kann die Identifikation von Indikatoren sein, die frühzeitig auf gewünschte oder ungewünschte Entwicklungen schließen lassen. Umgekehrt kann festgestellt werden, ob und welche Indikatoren von welchen Trainingsbelastungen oder sonstigen festgestellten Umständen abhängen.
Des Weiteren ist eine empirische Überprüfung bekannter Zusammenhänge realisierbar, wodurch die Relevanz von Messparametern für die Leistungsentwicklung und in der Trainingsteuerung überprüft werden kann. Dadurch sind Indizien gegeben, die eventuell nicht korrekt erkannte Zusammenhänge aufzeigen oder solche, die nur unter bestimmten Prämissen existieren. Vielfach haben Trainer und Sportmediziner diese Prämissen „im Gefühl“ und können sie nicht formulieren oder sehen sich auch nicht veranlasst, sie zu formalisieren. In Betracht auf die Wissenschaft sind jedoch gerade die empirische Korrektheit und das Erkennen von Gültigkeitsbereichen wichtig. Dadurch wird die Gefahr reduziert, dass unvollständig weitergegebenes Wissen in der Literatur gefestigt und von nächsten Generationen unkritisch übernommen wird.
7.2.1.2 Regressionsanalyse
Mit Hilfe der Regressionsanalyse können funktionale
Abhängigkeiten zwischen metrischen Variablen aufgedeckt werden. In unserem
Modell ist sie daher nur bedingt einsetzbar, da viele Variable nicht in metrischer
Form verwertbar sind, sondern meist durch qualitative oder Rangmerkmale kodiert
sind. Zum anderen muss ein funktionales Modell vorhanden sein, dessen
Gültigkeit überprüft werden soll. Dieses
funktionale Modell y = f(x) ist nur in den seltensten Fällen vorhanden. Dennoch
wird die Regression für Teilausschnitte oder zur generellen Erklärung von
Zusammenhängen verwendet (vgl.
[ECK02], [WEIN96]).
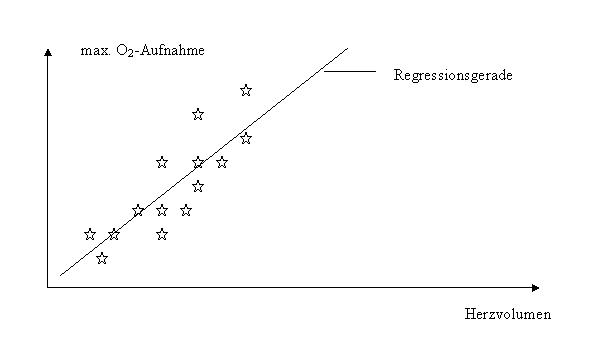
Abbildung 10 Schematische Darstellung eines Zusammenhangs,
erklärt durch die Regressionsgerade (aus [WEIN96], S.90)
7.2.1.3 Faktoranalyse
Die Faktoranalyse wird ebenfalls auf multivariante Systeme angewandt. Die Aufgabe der Faktoranalyse ist es, verdeckte Einflussgrößen zu identifizieren, die nicht direkt gemessen werden können.
Die Faktoranalyse ist ein Instrument, welches erfolgreich in der Marktforschung eingesetzt wird, um große Fragebatterien auf komplexere Faktoren zu reduzieren. Die erkannten Faktoren können dann durch ihre Eigenschaften identifiziert werden, die den Faktor am stärksten beeinflussen (wird auch als „Laden“ bezeichnet). (vgl. [WIED01], [HILD00], [WILB96]).
Eine unidirektionale Zuordnung von Variablen (bzw. Merkmalen) und Faktoren ist nicht vorausgesetzt. Ein Merkmal kann eine Ladung auf mehrere Faktoren besitzen und ein Faktor wird typischerweise von mehreren Variablen geladen. [WILB96] unterstreicht jedoch, dass es sich hierbei nicht um eine „verteilte Repräsentation“ handelt, die bei neuronalen Netzen auftritt (siehe 7.6).
Als Beispiel ist eine „hohe Regenerationsfähigkeit“ nicht unmittelbar messbar. Allerdings kann aus diversen Werten wie „CK-Wert nach Belastung“, „Lactatabbaurate“, „Leistung bei wiederholter Belastung“ usw. darauf geschlossen werden.
7.2.1.4 Clusteranalyse
„Ziel der Clusteranalyse ist die Zerlegung von Mengen an Objekten bei gleichzeitiger Betrachtung aller relevanten Merkmale so in Teilmengen, dass die Ähnlichkeit zwischen den Objekten eines Clusters möglichst groß, die zwischen den Gruppen jedoch möglichst gering ist.“ (vgl. [WIED01, S. 28]).
Die Clusteranalyse ist das gebräuchlichste Instrument zur Klassifizierung von Objekten. (siehe 6.2.1) Im Zuge der Analyse wird jedes Objekt, z.B. ein Athlet oder eine Trainingseinheit einer bestimmten Klasse zugewiesen.
Ziel kann es sein, Trainingseinheiten über medizinische Messwerte nach ihrer Intensität zu klassifizieren. Die Klassifizierung kann auch einen Ausgangspunkt für die Definition von Fuzzy-Mengen sein.
7.2.2 Grenzen klassischer Statistik
Da diese Zusammenhänge in der Medizin oft nicht-linear, zeitverzögert und im Zeitablauf veränderbar sind, stoßen die beschriebenen Methoden zur Prognose vielfach an ihre Grenzen.
Oftmals ist eine Abhängigkeit einer Ausgangsvariablen, zum Beispiel ein medizinischer Messwert, nur durch Kombination vorangegangener interner Zustände und des zu untersuchenden einwirkenden Faktors zu erkennen.
Ein Problem in diesem Zusammenhang stellt auch die Tatsache dar, dass medizinische Werte nicht lückenlos, sondern mit relativ geringen Abtastraten aufgenommen werden (siehe 4.3).
7.3
Zeitreihenanalyse
„Bei der Zeitreihenanalyse wird eine zeitliche Folge von
Beobachtungen, die als Zeitreihe bezeichnet wird, statistisch untersucht.“ (vgl.
[ECK02, S.185]).
Der Begriff der Zeitreihenanalyse kann in zwei grundsätzliche Kategorien geteilt werden. Einerseits kann versucht werden, eine Zeitreihe anhand der Umgebungsbedingungen zu erklären. Dabei wird von der „äußeren Methode“ oder Ökometrie gesprochen.
Die andere Alternative ist, die Zeitreihe aus sich selbst zu erklären. Ziel ist es, Gesetzmäßigkeiten in Abhängigkeit von der Zeit aufzudecken und es wird auch von der „inneren Methode“ gesprochen (vgl. [ECK02]).
7.3.1 Ziele der Zeitreihenanalyse
Ziele der Zeitreihenanalyse sind Beschreibung, Diagnose und Prognose. Die Beschreibung bezieht sich darauf, Regelmäßigkeiten in der Vergangenheit auszuspüren. In der Sportwissenschaft können dies Jahresverläufe, Trends, etc. sein. Die Diagnose soll feststellen, in welcher Phase der angenommenen Zeitreihe die aktuelle Situation liegt. Die Frage kann sein, ob eine Leistungszunahme bevorsteht oder ob der Höhepunkt gerade überschritten wurde. Eng daran gebunden ist dann eine Prognose der zukünftigen Entwicklung (vgl. [ECK02]).
Um Zeitreihen berechnen zu können, werden sie in Komponenten geteilt. Der Auswahl dieser Komponenten liegt ein Zeitreihendiagramm zu Grunde, welches die dynamischen Komponenten (siehe 2.3.7) des sportwissenschaftlichen Modells wiederspiegeln.
Je nach Verhalten der einzelnen Komponenten kann der Gesamtverlauf durch multiplikative oder additive Verknüpfung der Komponenten dargestellt werden (vgl. [ECK02]).
7.3.2 Zeitreihen für die Kontrollwerte
Ausschläge von Messwerten, die von der erwarteten Zeitreihe abweichen, stellen Anhaltspunkte für außergewöhnliche Situationen dar. Diese Methode wird in der Praxis implizit laufend durchgeführt, jedoch selten mit empirischer Belegung. Als eines der bekanntesten Beispiele ist die Ruheherzfrequenz zu nennen. Diese ist eine der einfachsten Möglichkeiten, Krankheiten oder Überbelastungen vorherzusagen.
Die Funktion dieser Methode beruht auf einer täglichen Messung der Herzfrequenz am Morgen. Durch „Erfahrung“ wissen der Athlet und der Trainer in welchen Bereichen sich die Herzfrequenz normalerweise bewegt. Ist eine „starke“ positive oder negative Abweichung über einen „gewissen Zeitraum“ festzustellen, so wird davon ausgegangen, dass dies ein Indiz für eine Fehlfunktion des Organsystems ist.
Wie in dieser Formulierung unterstrichen wurde, sind zahlreiche Unschärfen in diesen Aussagen zu finden. Durch Zeitreihenanalysen und den automatischen oder auch manuellen Vergleich mit tatsächlich eingetretenen Ereignissen können diese vagen Aussagen etwas konkretisiert werden. Zum Beispiel kann festgestellt werden, dass eine Abweichung um x % vom Standardwert (Mittelwert oder Medium) mit einer Wahrscheinlichkeit von y % Vorzeichen einer Erkrankung ist. Vielleicht ist es auch so, dass die Abweichung über mindestens t Tage verzeichnet werden muss, damit von einer Relevanz für den tatsächlichen körperlichen Zustand gesprochen werden kann.
Durch eine rein intuitive Beurteilung der Datenreihen werden oft auch langfristige Trends übersehen, da diese einen Blick über den normalen Erinnerungszeitraum reichen. Oft sind auch subjektive oder intuitiv unterstellte Trends Ursachen für fundamentale Irrtümer.
![]()

![]()
![]()
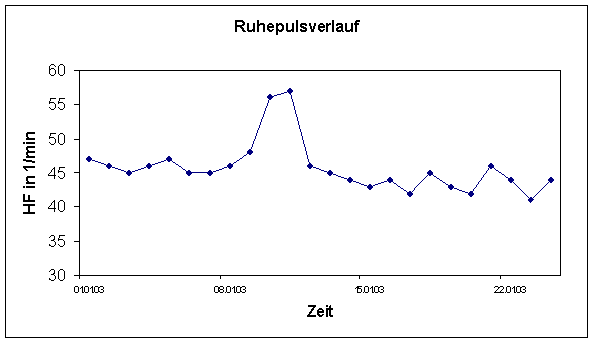
Abbildung 11 Zeitreihe „Ruhepulsverlauf“ mit Trendkanal und signifikanten Abweichungen
7.3.3 Bereinigung um dynamische Komponenten
Bereits aus Anwendungen in den Wirtschaftswissenschaften sind Phänomene der saisonalen Zeitreihen bekannt (vgl. [EDEL97]). Auch die Leistungsbereitschaft von Athleten variiert zyklisch im zeitlichen Verlauf.
Je nach Blickpunkt sind entweder zyklische Komponenten oder glatte Komponenten interessant. Um diese zu filtern, stehen mathematische Methoden zur Verfügung, die eine Zeitreihe auf die wesentlichen Komponenten reduzieren.
Soll die Leistung eines Athleten bei einem Leistungstest im Vergleich zu den letzen Jahren beurteilt werden, so ist es sinnvoll, die gewonnenen Werte um die kurzfristigen Schwingungen (Saison, Mesozyklus, Wochen- und Tagesrhythmus) zu bereinigen (siehe 2.3.7).
7.4
Genetische Algorithmen
Genetische Algorithmen repräsentieren die Regel der natürlichen Auslese. Nach dem Prinzip „survival of the fittest“ werden jene Variablen- bzw. Eigenschaftenkombinationen, welche die besten Ergebnisse liefern miteinander kombiniert. Daraus werden „Nachkommen“ (Mutationen) gebildet, welche Teileigenschaften von den „Eltern“-Elementen enthalten.
Abbildung 12 Ablauf eines genetischen Algorithmus aus [MORO99]
Die häufigste Problemstellung, die mit genetischen Algorithmen gelöst werden, kann ist die Optimierung. Die Optimierung ist auch eine zentrale Aufgabe in Entscheidungssystemen.
Ein großer Vorteil evolutionärer Algorithmen ist, dass auch nominale und ordinale Variablen untersucht werden können. (vgl. [LODD98]).
Anwendung könnte diese Methode finden bei der Auswahl geeigneter Belastungskombinationen. Es handelt sich dabei um eine Abbildung der geschichtlichen Entwicklung der Trainingslehre. Es wurde ausprobiert, welche Methoden in welchen Kombinationen zu gewünschten Ergebnissen führen und die besten ausgewählt und mit anderen als positiv erkannten Methoden kombiniert. Methoden, die keine oder nur unzureichende Fortschritte geliefert haben wurden eliminiert und durch die neu erprobten Arrangements ersetzt.
Durch das Durchlaufen eines genetischen Auswahlalgorithmus über vorliegende Beispieldaten könnte eine Selektion von erfolgreichen beziehungsweise eine Elimination von weniger erfolgreichen Kombinationen erfolgen. Auf diese Weise ist es möglich, weitere Erkenntnisse für die Trainingswissenschaft zu gewinnen.
In [FRUH99] wird vom Einsatz genetischer Algorithmen zur Identifikation von Leistungsfaktoren für die Laufleistung von Athleten und zur Parameterschätzung gesprochen. Dazu wird ein modifizierter genetischer Algorithmus verwendet, welcher nicht auf Bitstrings beruht, sondern auf einer individuellen Kodierung von Parametern.
7.5
Fuzzy-Methoden
Die Grundidee der Fuzzy-Methoden (in der Literatur wird meinst von Fuzzy-Inferenz-Methoden gesprochen, vgl. [BOT98]), ist komplexe Systeme einfach zu beschreiben. Dabei wird Anleihe an der menschlichen Wahrnehmung genommen. Das menschliche Gehirn ist in der Lage, eine Flut von teilweise unvollständigen Informationen in sehr kurzer Zeit konkreten Objekten zuzuordnen.
Eine Idee der Fuzzy-Methoden ist auch, die jeweiligen Qualitäten von Computern und Menschen zu kombinieren. Während Computer in der Lage sind, Rechenoperationen und vorgegebene Algorithmen sehr schnell auszuführen, ist die menschliche Entscheidungsfähigkeit derzeitigen Maschinen methodisch überlegen (vgl. [BOT98]).
Diese Eigenschaften kommen dem Einsatz in der Modellierung von sportwissenschaftlichen Modellen entgegen. Wie in den Kapiteln 2 bis 4 erläutert wurde, beruhen die Modelle auf Erfahrungswerten und weisen im Speziellen wesentliche Abweichungen auf. Daher können nur selten quantitative Aussagen getroffen werden. Diese Theorie wird auch im Gespräch mit Trainern und Sportmedizinern bestätigt. Es wird in der Praxis bezweifelt, ob quantitative Prognosen möglich und sinnvoll sind.
Das vorliegende Wissen und die existierenden Erfahrungen entsprechen jedoch im Prinzip den Fuzzy-Regeln, was im Folgenden noch gezeigt wird.
Die Eignung von Fuzzy-Methoden zur Konstruktion eines Expertensystems auf Basis von Regeln macht diese interessant für die Gewinnung von Expertenwissen.
[BOT98] hebt unter anderem den Vorteil hervor, dass mittels Fuzzy-Methoden auch nicht exakt definierte Systeme modelliert werden können. Die Modellierung erfolgt natürlichsprachlich und kann durch hinzufügen von Regeln erweitert werden.
In der Wissenschaft wird auch immer öfter eine Kombination von Fuzzy-Systemen mit Neuronalen Netzen erwähnt. (siehe 7.7)
7.5.1 Fuzzy-Mengen
Die Basis der Fuzzy-Logik und der Fuzzy-Methoden sind unscharfe Mengen. Unscharf bedeutet in diesem Zusammenhang, dass ein Element nicht entweder zur Menge gehört oder nicht, sondern dass ein Element zu einem gewissen Grad einer Menge angehört.
7.5.2 Fuzzy-Regeln
In Fuzzy-Systemen wird Wissen in Form von Regeln repräsentiert. Diese sind jedoch nicht zwangsläufig mathematisch formuliert, sondern können auch in einer unscharfen Form vorliegen. Üblicherweise werden Wenn-dann-Regeln verwendet.
Im Beispiel der Trainingslehre könnte eine solche Regel lauten:
WENN (ein bestimmter Blutwert) „hoch“ DANN kein „intensives Training“.
Da in der Sportwissenschaft ein großer Teil des Wissens in einer solchen unscharfen Form vorliegt, bietet sich diese Methode der Wissensrepräsentation an.
Fuzzy-Regeln müssen nicht in sich konsistent sein, sondern können auch miteinander konkurrieren oder überlappende Gültigkeitsbereiche haben (vgl. [BOT96]). Auch diese Qualität ist in der Sportwissenschaft von Vorteil, da das gesammelte Erfahrungswissen weder widerspruchsfrei noch vollständig ist.
Die Regeln des Systems bestimmen dessen Übertragungsverhalten. Ein Fuzzy-System an sich setzt unscharfe Eingangsgrößen in unscharfe Ausgangsgrößen um. Aus diesem Grund bleibt zusätzlich Information bestehen und wird nicht auf binäre Variable reduziert.
7.5.3 Linguistische Variablen
Ein Vorteil der Fuzzy-Methoden ist, dass Informationen und Regeln in menschlicher Sprache abgebildet werden können. Auf diese Weise kann Erfahrungswissen und unscharfes Wissen in elektronischer Form nutzbar gemacht werden.
Sowohl die Ausprägung der Variablen als auch die Beschreibung von Funktionen und Operatoren kann in natürlicher Sprache erfolgen und macht ein komplexes System leichter verständlich.
Die Verwendung von relativen Begriffen wie „mehr“, „weniger“, „sehr“, etc. öffnet neue Möglichkeiten der Beschreibung von Zusammenhängen.
In komplexen Systemen können neben den sichtbaren Eingangs- und Ausgangsvariablen auch verstecke Variable eingeführt werden.
7.5.4 Vorgehensweise
Wird ein System von Fuzzy-Methoden verwendet, werden zu Beginn die linguistischen Variablen definiert und entsprechenden unscharfen Mengen zugewiesen.
Das Wissen, sprich die Regelbasis, kann entweder vor Experten direkt eingespeist werden oder automatisch durch Datenanalyse generiert werden.
Bei der Anwendung eines Fuzzy-Systems erfolgt die Verarbeitung von Daten in drei Schritten. Zuerst werden vorliegende Messdaten in Zugehörigkeitswerte der Fuzzy-Mengen umgewandelt. Dabei wird von Eingangskodierung oder Fuzzyfikation gesprochen.
Die so erhaltenen Fuzzy-Signale werden über die Regelbasis über Fuzzy-Inferenzmethoden verarbeitet. Es existiert eine Vielzahl von Inferenzmethoden. Für die unscharfe Modellierung bezeichnet [BOT98] die „Tkagi-Sugeno-Inferenzmethode“ als geeignet, wobei für detaillierte Informationen auf die Literatur verwiesen sei.
Die aus der Inferenzmethode erhaltene Ausgabe stellt ebenfalls eine unscharfe Größe dar. Soll diese Ausgabe nun automatisch weiterverarbeitet werden, muss die durch die Dekodierung oder Defuzzyfikation wieder in einen scharfen Wert verwandelt werden. Auch hier stehen verschiedene Methoden zur Verfügung, deren Anwendung in erster Linie vom Charakter der Daten abhängt.
7.5.5 Automatische Adaption
Nachdem die Struktur des Systems festgelegt ist (linguistische Variablen, Inferenzfunktion und Dekodierungsfunktion), können Regeln automatisch erzeugt werden. Durch das Anlegen von Trainingspaaren (Eingangswert und Ausgangswert) wird für jedes Paar eine eigene Regel definiert. Die daraus entstandenen Regeln werden in der Folge bewertet und dabei doppelte und gegensätzliche Regeln eliminiert (vgl. [BOT98]).
7.6
Neuronale Netze
Künstliche neuronale Netze entstanden aus der Idee, das menschliche Gehirn nachzubilden und dessen Fähigkeiten in der Automatisierung nutzbar zu machen. Dies betrifft vor allem die Methodik der Entscheidungsfindung und der Lern- bzw. Anpassungsfähigkeit.
Neuronale Netze stellen generische Modelle dar und eignen sich aus diesem Grund zur Generierung von systembeschreibenden Modellen auf Basis von Beispieldaten.
Der Lernprozess neuronaler Netze ermöglicht eine Anpassung der Strukturen bzw. der Ausprägung von Verknüpfungen und somit eine laufende Weiterentwicklung eines Modells (vgl. [LUG01]).
Aufgrund der nicht oder schwer vorhersehbaren Entwicklungen innerhalb des Netzes, kann der Struktur eines neuronalen Netzes keine Bedeutung entnommen werden. Erst in seiner Transformationsfunktion dient das Netz als dynamische Repräsentation eines Modells.
Dies wird auch darin sichtbar, dass verschiedene Reihenfolgen der gleichen Beispieldaten vielfach zu völlig unterschiedlichen Strukturen führen und die Funktion des Gesamtsystems trotzdem sehr ähnliche Ergebnisse liefert.
Das große Problem neuronaler Netze, bzw. der heute bestehenden Lernalgorithmen ist, dass eine Lösung der Aufgabe nicht garantiert ist. Eine Verbesserung der Ergebnisse ist sehr stark von der Parametereinstellung des Netzes abhängig (vgl. [BOT98]).
7.6.1 Eigenschaften
Neuronale Netze weisen bestimmte Eigenschaften auf, die einer Lösung sportwissenschaftlicher Problemstellungen (siehe 2) dienlich sein können. Sie sind in der Lage, nichtlineares Verhalten und nichtlineare Beziehungen zu modellieren. Dies entspricht den Eigenschaften von sportwissenschaftlichen Modellen, welche durch nichtlineare Zusammenhänge und versteckte (intransparente) Abläufe und Zustände gekennzeichnet sind.
Die Lernfähigkeit neuronaler Netze kommt zum einen der Dynamik des Systems entgegen, da das Modell die Anpassungsvorgänge abbilden kann. Zum anderen werden auch unsichtbare Zustände und unbekannte Tatsachen automatisch im Lernprozess erkannt.
Um die hohe Komplexität des Modells zu bewältigen, muss ein Simulationssystem in der Lage sein eine hohe Zahl von Variablen zu verarbeiten. Auch diese Eigenschaft ist bei neuronalen Netzen gegeben, wenn diese auch durch hohe Rechenzeiten an ihre Grenzen stößt.
In der folgenden Grafik werden die Eigenschaften von Neuronalen Netzen und die Eigenschaften von komplexen Problemstellungen im Entscheidungsprozess übersichtlich dargestellt. Auch wenn diese Grafik auf eine wirtschaftswissenschaftliche Problemstellung abzielt, sind die Ähnlichkeiten doch evident.
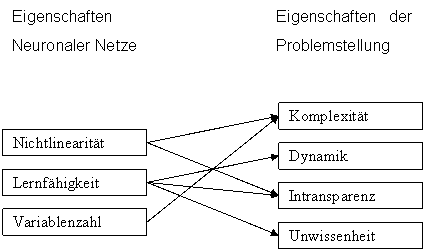
Abbildung 13 Beziehung der Eigenschaften von Neuronalen Netzen zu denen der Problemstellung [WIED02/2]
Eine Besonderheit neuronaler Netze in bezug auf Modellbildung ist die Tatsache der verteilten Repräsentation (vgl. [WILB96]). Dies bedeutet, dass einem Merkmal der Realität im Modell mehrere Elemente zugeordnet werden. Umgekehrt können auch mehrere Merkmale der Realität in einem Element des Modells Niederschlag finden.
Dies führt nach [WILB96] zu einigen Problembereichen.
Die strukturelle Homomorphie ist bei neuronalen Netzen nicht mehr gegeben, da die Netztypologie nicht mit tatsächlichen Elementen des Realsystems übereinstimmt. Die Abbildung wird auf Verhaltenshomomorphie reduziert und die Modellierung ist nur auf höchster Ebene möglich, ohne einzelne Elemente zu identifizieren.
Dadurch ist die Validierung dieser Modelle nur eingeschränkt möglich und ist auf den Vergleich empirischer Ergebnisse limitiert. Das Modell kann nicht in seiner Struktur auf logische Stimmigkeit geprüft werden.
7.6.2 Grundlagen
Das Charakteristikum von neuronalen Netzen sind künstliche Neuronen und deren Verbindungen. Ein Neuron besteht aus folgenden Elementen (vgl. [LUGER02]):
- Eingangssignal von außen oder einem anderen Neuron
- Gewichte repräsentieren die Verbindungsstärke zu anderen Neuronen
- Aktivierung als interne Reaktion auf die Eingangssignale
- Schwellwertfunktion zur Ermittlung des Ausgangswertes aus der Aktivierung
Das gesamte Netz wird durch weiter bestimmt durch:
- Netzwerktypologie bestimmt die Struktur der Neuronenverbindungen
- Lernalgorithmus gibt vor, wie das Netz Wissen erwirbt
- Kodierungsschema für die Interpretation von Ein- und Ausgangsdaten
Auf Basis dieser Parameter kristallisierten sich im Laufe der Zeit Spezialformen heraus, die jeweils für bestimmte Aufgabenbereiche besonders geeignet scheinen. Netzwerktypologie und Lernalgorithmus stehen in starkem Zusammenhang und sind in der Regel nicht trennbar.
Eine wichtige grundsätzliche Unterscheidung in der Typologie wird in der Literatur vielfach in Feed-Foreward-Netze und rückgekoppelte Netze getroffen, wobei sich diese Rückkopplung nicht auf die Modellanwendung bezieht, sondern auf die Beeinflussung in einem Lernzyklus.
Konkret ausgedrückt bedeutet dies, dass bei zeitdiskreten Systemen in Form von Feed-Foreward-Netzen die Ausgangswerte durchaus als Eingangswerte des nächsten Zeitschrittes dienen können. Das Netz selbst weist jedoch keine internen Rückkopplungen auf, wodurch der Anpassungsprozess sicher terminiert und keine Schwingungen entstehen.
Diese Eigenschaft ist beim Einsatz des Multi-Layer-Perceptron von entscheidender Bedeutung.
Im Folgenden werden einige spezielle Netztypen angesprochen und deren Einsatzbereiche abgegrenzt.
7.6.3 Anwendungsbereiche
7.6.3.1 Multi-Layer-Perceptron
Das
Multi-Layer-Perceptron (MLP) in Kombination mit dem
Backprogation-Lernalgorithmus, ist die bekannteste Form von neuronalen Netzen.
Es handelt sich
dabei um ein mehrschichtiges Feed-Foreward-Netz. Der Ausgang jedes Neurons einer Schicht wird als
Eingang an jedes Neuron der Folgeschicht weitergeleitet.
Dabei wird von
Input-Layer oder Eingangsschicht und Output-Layer oder Ausgangsschicht
gesprochen, während die Zwischenschichten als Hidden-Layer bezeichnet werden.
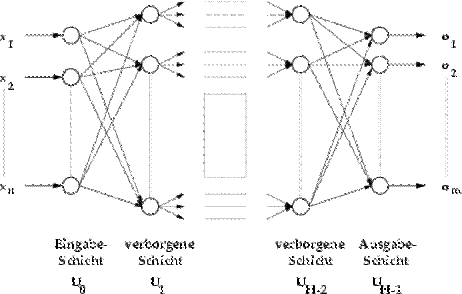
Abbildung 14 Grundstruktur eines Multi-Layer-Perzeptron
(aus [LIPP02])
Als Schwellwertfunktion
wird meist eine sogenannte S-Funktion verwendet. Meist werden entweder y = 1/tanh(x) oder y = 1/e(-x)
aufgrund der einfachen mathematischen Ableitbarkeit bevorzugt.
Durch diese
Netzwerktypologie können komplexe Systeme in ihrem Übertragungsverhalten
beschrieben werden.
Eingesetzt wird
das MLP vorwiegend in der Dependenzanalyse. Aufgrund der besonderen
Eigenschaften von neuronalen Netzwerken, können komplexe, multivariate und
nicht-lineare Systeme mit dem MLP modelliert und simuliert werden.
Im Bereich der
Reproduktion sportwissenschaftlicher Modelle (siehe 2) kann das MLP in Funktion eines zeitdiskreten Systems
eingesetzt werden. Als Zeitrasterung erweist sich aus der
sportwissenschaftlichen Praxis (siehe 3) die Diskretisierung in Tage als gebräuchlich.
Ein solches
Modell könnte folgendermaßen aussehen:
Reine Eingangsdaten liegen in Form von
Trainingsdaten oder diverser Dokumentationsdaten (z.B. Schlafstunden,
Medikamentengabe, Regenerationsmaßnahmen, etc.) vor.
Als Ausgangsdaten kann eine Prognose der
Leistungsfähigkeit interessant sein.
Des Weiteren sind
Zustandsvariablen zu identifizieren,
in denen der aktuelle Zustand des Systems gespeichert ist. Ein überwiegender
Teil der medizinischen Messwerte dient dazu. Diese Variablen scheinen im
neuronalen Netz dreimal auf.
Erstens als
Eingangsdaten, in denen die gemessenen Werte eingespeist werden. Eingangsdaten
liegen allerdings nicht immer vor. Daher müssen die Eingänge gesondert
aktiviert, bzw. deaktiviert werden.
Zweitens wird ein
Schätzwert dieser Daten an den Ausgang übertragen.
Drittens liegt
der Ausgangswert der vorhergehenden Periode in der aktuellen Periode wieder als
Eingang vor, um den Zustand des Systems in die nächste Berechnung mit
einzubeziehen.
Der automatische
Prozess der Modellbildung gliedert sich bei MLPs in 3 Stufen.
Zu diesem Zweck
werden die vorliegenden Daten in Trainings- und Validierungsdaten gespalten.
Ein Datensatz besteht immer aus Eingangsdaten und aus den gewünschten bzw.
gemessenen Ausgangsdaten, die das Netz liefern soll.
In der ersten
Stufe erfolgt das Training der Gewichte anhand von Trainingsdaten. Die Gewichte passen sich also diesen Daten an.
Damit eine genügend genaue Anpassung erreicht wird, können mehrere Durchläufe
erreicht werden. Wird der Trainingsvorgang zu oft wiederholt, kommt es zum so
genannten „Übertraining“. Das Netzt kann also die Trainingsdaten zwar perfekt
simulieren, schätzt aber unbekannte Daten mit großen Abweichungen.
Zu diesem Zweck
wird nach jedem Trainingsdurchlauf eine Überprüfung anhand der Validierungsdaten vorgenommen.
Jene
Konfiguration, welche die geringsten Abweichungen von Netz-Ausgangswerten und
Kontroll-Ausgangswerten aufweist wird als Optimum gespeichert. Zur Auswahl der
optimalen Konfiguration können verschiedene Strategien angewandt werden.
Entweder wird der Durchschnittsfehler von Trainings- und Validierungsdaten
minimiert oder nur der Durchschnittsfehler der Validierungsdaten.
Abhängig von der
Art des Datenzusammenhangs erfolgt die Teilung der Daten in Trainings- und
Validierungsdaten. In unabhängigen Datenreihen (Stichproben) können die
Datensätze zufällig einer Gruppe zugewiesen werden. Anders verhält es sich bei
zeitabhängigen Datenreihen. Da der Zustand eines Punktes in der Datenreihe
Auswirkungen auf die nächsten Punkte aufweist, kann die Reihenfolge nicht
variiert werden und es dürfen auch keine Datenpunkte ausgelassen werden (siehe
auch 4.6.2).
7.6.3.2 Kohonen-Netz (SOM)
Kohonen-Karten oder Selbstorganisierenden Karten oder Self-Organizing-Maps (SOM) sind den Methoden zuzuordnen, die vorwiegend zur Interdependenzanalyse herangezogen werden können. Topologisch handelt es sich um ein niederdimensionales (meist 2), einschichtiges Netz. Der n-dimensionale Gewichtsvektor eines Neurons beschreibt die Lage des Neurons bezüglich der n Eingangsvariablen. Die Gewichte werden durch die Angabe einer Nachbarschaftsbeziehung zu den umliegenden Neuronen genauer definiert.
In einem unüberwachten Lernverfahren passen sich die Parameter so an, dass sich das Netz an die n-dimensionalen Punktwolke der Eingangsdaten anschmiegt. Auf diese Weise wird die Dichtefunktion einer Stichprobe repräsentiert. Es handelt sich also um ein spezielles Verfahren zur Klassifikation (vgl. [WIED01]).
Der Einsatz von SOM zur Klassifizierung von Eingangsdaten ist vor allem dann interessant, wenn vor der Analyse die Anzahl der Klassen nicht bekannt ist. Der normale Kohonen-Algorithmus ist sensibel auf die Parametereinstellung und garantiert nicht in allen Fällen eine Ordnung der Kohonen-Karte.
Dieses Problem kann durch die Kombination mit
Fuzzy-Algorithmen gemindert werden (vgl. [SCHI99]).
7.7
Neuro-Fuzzy-Methoden
Wie der Name vermuten lässt, handelt es sich dabei um eine Kombination von neuronalen Netzen und Fuzzy-Systemen.
Meist fungiert dann ein System als Hauptkomponente und das andere als Unterstützung. Welches Prinzip die Hauptkomponente bildet, hängt von der Aufgabenstellung ab.
Ein neuronales Netz zur Unterstützung eines Fuzzy-Systems kann z.B. dazu dienen, die Parameter des Fuzzy-Systems oder die Regelbasis zu trainieren.
Umgekehrt können Fuzzy-Methoden dazu dienen, die Parameter
oder die grundsätzliche Struktur eines Neuronalen Netzes zu bestimmen (vgl. [BOT98]).
Ein entscheidender Vorteil gegenüber Neuronalen Netzen liegt
darin, dass die Ergebnisse des Lernprozesses nicht in einem Netz begraben
liegen. Wie in 7.6 erläutert wurde, kann aus der Struktur des Neuronalen
Netzes nicht auf darin enthaltenes Wissen geschlossen werden. In Neuro-Fuzzy-Methoden kann das gewonnene Wissen
dagegen in nachvollziehbaren Wenn-dann-Regeln gespeichert und von Experten
überprüft werden.
Abschnitt II. - Praxisprojekt
8
Allgemeines zum Projekt
Im Zuge der Diplomarbeit wurde ein Softwaresystem entwickelt, welches einige der im Theorieteil angesprochenen Aspekte implementiert.
Das System wurde in Zusammenarbeit mit dem sportwissenschaftlichen Institut von Mag. Bernhard Schimpl in Linz entworfen.
8.1
Aufgabe
Das System soll als Unterstützung für den gesamten Trainingsplanungsprozess dienen. Erster Punkt in dieser Kette ist die Trainingsplanung. Der Planung soll eine Beschreibungsdatenbasis zugrunde liegen, welche es erlaubt, Trainingseinheiten genau und standardisiert zu entwerfen.
Diese Pläne sind dann in entsprechender Form dem Athleten zugänglich zu machen.
Im Laufe des Trainings werden Dokumentationsdaten aufgenommen und durch Beschreibungen und Notizen ergänzt. Diese Daten werden wieder in das System übernommen und stehen so für die Datenanalyse zur Verfügung.
Bei der Datenanalyse werden Abweichungen vom Plan festgestellt und diskutiert. Weiters werden außergewöhnliche Messwerte untersucht, um deren Ursache festzustellen.
8.2
Anforderungen
Eine grundlegende Anforderung an das System war es, eine erweiterbare Datenbank zur Verfügung zu stellen. Da das System gleichzeitig für verschiedene Sportarten einsetzbar sein soll, muss der Datenbestand an die jeweiligen Gegebenheiten angepasst werden können.
Innerhalb dieser verschiedenen Anwendungsbereiche soll jedoch eine möglichst hohe Standardisierung erreicht werden.
Die Erhebung einer möglichst großen und qualitativ hochwertigen Datenbasis ist das Fundament für eine vernünftige Analyse der Daten. Auf dieser Basis wird ein zeitvariates, dynamisches Zusammenhagsmodell gebildet.
Weist der Datenbestand Fehlwerte auf oder ist dieser nur unvollständig vorhanden, so wird das Ergebnis der Modellbildung nicht brauchbar sein. Aus diesem Grund ist hoher Wert auf die Qualität der Rohdaten zu legen.
9
Datenbank
Das Herzstück des Systems ist die Datenbank in dem die Bestände von Trainingsdaten, Dokumentationsdaten, Testdaten und Konfigurationen abgelegt sind. Eine der Herausforderungen war, die Datenbank für mehrere Sportarten nutzbar zu machen und trotzdem den gewünschten Detaillierungsgrad in den Aufzeichnungen zu erhalten.
9.1
Anforderungen
9.1.1 Anpassungsfähigkeit
Verschiedene Trainer verwenden unterschiedliche Trainingssysteme. Aus diesem Grund ist die Datenbank so gestaltet, dass auf einem leeren System aufgesetzt wird. Der Benutzer kann auswählen, ob er eine Standarddatenbank nutzen will, in der bereits meistverwendete Einträge vorgenommen sind. Vor allem Basismesswerte sind bereits vordefiniert.
Abgesehen davon kann frei gewählt werden, welche Ausprägungsformen die verschiedenen Messgrößen haben.
Auch Trainingsmethoden sind in keiner Weise vorgegeben, sondern können frei definiert werden.
9.1.2 Erweiterbarkeit
Wenn die Datenbank konfiguriert und entsprechend der eigenen Bedürfnisse angepasst wurde, kann es sein, dass Veränderungen vorgenommen werden sollen.
Diese Eigenschaft wird unter Erweiterbarkeit verstanden. So ist es jederzeit möglich, neue Messwerte, neue Trainingsmethoden, etc. zu definieren.
Um die Konsistenz der Daten zu gewährleisten, muss diese Erweiterbarkeit in einigen Punkten jedoch beschränkt werden. Die Bedeutung vorhandener Daten wird in Form von Metadaten festgehalten. Es dürfen zwar neue Metadaten definiert werden, diese jedoch nicht vorbehaltlos gelöscht werden.
9.2
Struktur der Daten
Im Diesem Kapitel wird beschrieben, wie die unterschiedlichen Klassen von Daten in Tabellen abgelegt sind. Als Basis für das System dient eine relationale Datenbank.
9.2.1 Initialisierungsdaten
Persönliche Einstellungen für den Benutzer werden in einer Tabelle abgelegt.
Die Identifikation der Initialisierungswerte erfolgt durch einen im System vergebenen, eindeutigen Namen und durch die ID des Benutzers.
Die Einstellungen bezüglich Anzeige, Farbe, Anzeigebereiche, Standarddatumsbereiche, etc. werden gespeichert und sind bei der nächsten Anwendung des Systems wieder geladen.
Sind keine Einträge des Benutzers vorhanden, so liegen Standardwerte in der Tabelle, die zur Anwendung kommen.
9.2.2 Trainingsdaten
Wie im Theorieteil beschrieben wurde, kann jede Trainingseinheit grundsätzlich durch 4 Faktoren identifiziert werden. Entsprechend ihrer Kategorie werden zusätzliche Daten angegeben (siehe 2.2).
9.2.2.1 Allgemeines
Trainingsdaten treten im Trainingsmanagementprozess zweimal in Erscheinung. Ersten im Zuge der Planung und dann nochmals in Form der Dokumentation. Um diese klare Trennung zu verdeutlichen liegen in der Datenbank zwei gleiche Tabellenstrukturen vor, einmal für Planung und einmal für die Dokumentation.
9.2.2.2 Grunddaten
Jede Trainingseinheit ist durch ein Mindestmass an Informationen identifiziert. Diese Basisinformationen wurden bewusst sehr schlank gehalten um dem Trainer die Möglichkeit zu geben, eigene Strukturen der Trainingsinhalte zu definieren.
Die Einträge in den Grunddaten sind Kategorie, Intensität, Trainingsmittel, Zielorgan und Gesamtzeit. Es werden jeweils nur Referenzen auf Einträge in zugehörigen Definitionstabellen eingetragen (siehe 9.2.2.5).
9.2.2.3 Kategoriespezifische Daten
Zu jeder Trainingseinheit werden je nach Kategorie zusätzliche Informationen gespeichert.
Zu diesem Zweck wird bei Definition einer neuen Kategorie eine zugehörige Tabelle angelegt. Dafür werden Metadaten in einer Tabelle gehalten, die den Kategorieparametern ihre Bedeutung geben.
Die Definition dieser Daten kann nur einmal erfolgen, wenn die Kategorie angelegt wird. Grund dafür ist das eingangs beschriebene Problem bei der Erweiterung (siehe 9.1.2). Werden die Metadaten verändert, kann passieren dass einem früher eingetragenen Parameter eine neue Bedeutung gegeben wird, wodurch ein Bruch in der Datenkonsistenz entsteht.
Beispiel: Parameter 1 der „Intervallmethode“ wurde als „Belastungszeit“ definiert. Könnte die Bedeutung des Parameters nun auf „Wiederholungszahl“ geändert werden, wären die alten Daten offensichtlich nicht mehr sinnvoll in diesem Kontext.
9.2.2.4 Traineridentifikation
In der eingesetzten Version ist es so, dass Trainingsdaten nicht direkt einem Trainer zugeordnet sind. In der Praxis ist meist ein hauptverantwortlicher Trainer für einen Athleten vorhanden, der den Plan abzusegnen hat, bevor er dem Athleten zur Durchführung vorgelegt wird.
In den meisten Fällen ist auch nur ein Trainer für die Planung zuständig. Dies kann in einzelnen Sportarten variieren. Betrachtet man Triathlon oder Zehnkampf, ist es durchaus möglich, dass mehrere Trainer mit einem Athleten arbeiten.
9.2.2.5 Definitionstabellen
Die vier Variablen zur Charakterisierung von Trainingseinheiten werden in der Trainingsdatentabelle als Verweise gespeichert.
Für jede der vier Variablen wird eine Tabelle angelegt, in der die Definition der Ausprägungsformen erfolgt. In den Definitionstabellen werden nur ein kurzer und ein langer Name gespeichert. Die Zuordnung von Messwerten, etc. erfolgt in eigenen Zuordnungstabellen. Auf diese Weise bleibt die Erweiterbarkeit gegeben.
9.2.3 Basisdaten – Metadaten
Unter Basisdaten wird die Beschreibung der im System verwendeten
- Basismesswerte
- spezifische Messwerte
- Charakteristika
verstanden.
Basismesswerte sind definiert durch ihre Einheit, ihren Gültigkeitsbereich und den Typ. Die Einheit wird in verbaler Form angegeben.
|
measureID |
nameLong |
nameShort |
entity |
validfrom |
validto |
type |
|
1 |
Zeit in Minuten |
t/min |
min |
0 |
0 |
0 |
|
2 |
Herzfrequenz |
HF |
1/min |
30 |
250 |
-1 |
|
3 |
Lactat |
Lac |
mmol/l |
0 |
30 |
-1 |
|
4 |
Zeit in Stunden |
t/h |
h |
0 |
0 |
-1 |
|
... |
|
|
|
|
|
|
Tabelle 4 Datenbank – Basismesswerte
In der Praxis werden gleiche Messwerte mit Verschiedenen Einheiten verwendet, um die Lesbarkeit zu verbessern. Zu diesem Zweck können zwischen verschiedenen Einheiten gleicher Messwerte Umrechnungsfaktoren definiert werden.
Ein Basismesswert erhält erst im Zusammenhang mit der Anwendung den eigentlichen Sinn. „Zeit in Minuten“ kann z.B. in innerhalb einer Trainingseinheit „Gesamtbelastungszeit“, „Pausezeit“, etc. beschreiben. Ein Basismesswert kann somit mehrfach vorkommen, wodurch es nötig ist, eine nochmalige Zuordnung vorzunehmen. Diese Vorgehensweise hat den weiteren Vorteil, dass der Benutzer nur Messwerte auswählen kann, die auch für diese Beschreibung vorgesehen sind.
Die Spezifizierung der Messwerte erfolgt in folgenden Klassen:
- Intensitätsmesswerte
- Kategoriemesswerte
- Messwerte für medizinische Werte
Intensitätsmesswerte werden dazu verwendet, um die Trainingsintensität zu beschreiben. In diese Kategorie fallen z.B. „maximale Herzfrequenz“, „minimale Herzfrequenz“, „maximales Lactat“, etc.
Jeder Intensität können beliebig viele Messwerte zugeordnet sein (siehe 9.2.3.1). Dies ist daher nötig, da unterschiedliche Trainingsbereiche unterschiedliche Bestimmungsfaktoren aufweisen. Der Intensitätsbereich „Regeneration“ ist nur durch eine „maximale Herzfrequenz“ definiert.
Kategoriemesswerte dienen dazu, eine Trainingseinheit genauer zu beschreiben. Jeder Kategorie können beliebig viele Faktoren zugeordnet werden (siehe 9.2.3.2).
Medizinische Messwerte sind entsprechende Ausprägungen der Basismesswerte, um Kontrollwerte zu beschreiben.
9.2.3.1 Intensitätswerte
Die Intensität, mit der eine Trainingseinheit durchgeführt wird kann durch verschiedene Parameter bestimmt werden. Daher können jedem Intensitätsbereich beliebig viele Steuerungsparameter zugeordnet werden. Üblicherweise sind diese Daten als Minimal- und Maximalwerte eines Messparameters angegeben. Sehr häufig findet die Herzfrequenz Anwendung.
Die Definition des Intensitätsbereichs erfolgt personenspezifisch. Für jeden Athleten ist ein Set von Intensitätsbereichen vorhanden.
Die Intensitätsbereiche ändern sich laufend. Der historische Verlauf dieser Parameter soll jedoch nachvollziehbar bleiben. Aus diesem Grund werden alte Parameter nicht durch neue überschrieben, sondern es werden laufend neue Einträge erstellt, die ein Gültigkeitsdatum enthalten.
Es ändern sich nicht notwendigerweise alle Trainingsbereiche gleichzeitig. Um nun die aktuell gültigen Trainingsbereiche aus der Datenbank zu gewinnen, genügt es, jene Einträge mit dem größten Datumswert zu lesen.
Wird ein Intensitätsbereich für einen Athleten nicht genutzt, so muss dieser nicht definiert werden. Sollte dieser Bereich wider erwarten doch verwendet werden, so wird dies im Trainingsplan gekennzeichnet.
Die zugehörige Datentabelle sieht wie folgt aus:
|
intID |
parID |
athletID |
value |
dateTime |
|
1 |
2 |
4 |
136 |
08.05.2002 |
|
2 |
1 |
4 |
136 |
08.05.2002 |
|
2 |
2 |
4 |
149 |
08.05.2002 |
|
3 |
1 |
4 |
149 |
08.05.2002 |
|
3 |
2 |
4 |
165 |
08.05.2002 |
|
4 |
5 |
4 |
284 |
08.05.2002 |
|
5 |
1 |
4 |
185 |
08.05.2002 |
Tabelle 5 Datenbank – Intensitätsbereiche
9.2.3.2 Kategoriewerte
Im Gegensatz zu Intensitätswerten sind Kategoriewerte nicht für den Athleten spezifisch definiert, sondern für die Trainingseinheit selbst.
Mit Hilfe dieser Werte kann die Trainingseinheit in ihrer besonderen Struktur genauer beschrieben werden.
Auf diese Weise ist dem Trainer maximale Freiheit in der Definition von Trainingseinheiten gegeben. Trotzdem ist innerhalb einer Kategorie eine maximale Standardisierung gegeben.
Ein anderer Ansatz wäre, eine definierte Anzahl an Kategorien vor zu geben. Diese Methode hätte den Vorteil, dass eine standardisierte Datenbasis vorliegt und schon zur Programmierzeit bekannt ist, welche Strukturen auftreten werden. Dadurch können Methoden zur Datenanalyse direkt programmiert werden. Es können einfachere Berechnungen durchgeführt werden.
In der hier gewählten Methode ist es nötig, Metadaten über die Bedeutung der Parameter zu führen. Beispielsweise setzt sich die Gesamttrainingszeit beim „Intervalltraining“ aus „Aufwärmphase + Wiederholung * (Belastungszeit + Pausezeit) + Abwärmphase“ zusammen.
Diese Information muss in der Datenbank beim Anlegen der Trainingskategorie gespeichert werden, um sie später für Analysen und Automatisierungsaufgaben verwenden zu können.
Offensichtlicher Nachteil ist, dass der Kreativität des Trainers eine Grenze gesetzt ist, da bereits zur Programmierzeit die genaue Datenstruktur festgelegt werden muss. Trainingsmethoden, die zu Beginn noch nicht bekannt sind, können nur mehr mit großem Aufwand angefügt werden.
Das andere Extrem bei der Speicherung von kategoriespezifischen Trainingsdaten besteht darin, für jede Trainingseinheit dieselben Informationen zu speichern. Dadurch entstehen einerseits große Lücken in der Datenbank, da für jede Kategorie nur ein kleiner Teil der gesamten Tabelle gefüllt wird. Andererseits müssen Informationen, für die kein Platz in der Tabelle vorgesehen ist, in verbaler Form angefügt werden. Wenn verbale Informationen vorliegen, die dazu benützt werden, eine Trainingseinheit zu charakterisieren, ist jedoch eine Weiterverarbeitung nicht mehr möglich.
9.2.3.3 Medizinische Messwerte
Dies sind Kontrollwerte, die täglich oder in unregelmäßigen Abständen in die Datenbank eingegeben werden. Die Daten werden linearisiert in der Datenbank abgelegt und nicht in Form fix vorgegebener Tabellen. Dies hat einerseits den Grund, dass zahlreiche Daten nur selten aufgezeichnet werden, andererseits wurde hier auf eine maximale Erweiterbarkeit der Datenbank Rücksicht genommen. Die Metadaten liegen in einer Tabelle mit folgendem Aussehen.
|
medMeasureID |
nameLong |
nameShort |
measureID |
|
1 |
RuheHerzfrequenz |
RHF |
2 |
|
3 |
Schlafzeit in Stunden |
Schlaf |
4 |
Tabelle 6 Datenbank – Definition medizinischer Messwerte
Die Daten liegen in linearisierter Form in einer weiteren Tabelle.
|
medMeasureID |
athletID |
value |
dateTime |
|
1 |
4 |
45 |
03.09.2002 |
|
1 |
4 |
46 |
04.09.2002 |
Tabelle 7 Datenbank – Daten medizinische Messwerte
9.2.4 Stammdaten
9.2.4.1 Personen
Alle
Personendaten werden in einer zentralen Tabelle gespeichert. In einer
Zuordnungstabelle werden die Personen mit Rollen verbunden. Personen können
auch mehrere Rollen erfüllen, z.B. Athlet und gleichzeitig Trainer, oder
Trainer und Teamleiter, etc.
Speziell in
größeren Systemen ist es nötig, Personendaten genau zu speichern und zu
gewährleisten, dass nur berechtigte Personen Zugang zu den verbundenen Daten
haben.
Ein Trainer darf
nur die Daten der ihm unterstellten Athleten sehen. Erreicht wird dies durch
ein Zuordnungstabelle von Athleten und Trainern und eine entsprechende
Vorselektion bei der Anzeige der bearbeitbaren Athleten.
9.2.4.2 Sportarten
Athleten, bzw.
Trainer können gewissen Sportarten zugewiesen werden. Sportarten werden nur mit
ihrem Namen gespeichert. Es ist in dieser Version nicht vorgesehen, die
Sportarten künstlich zu klassifizieren. Die Speicherung der Sportzugehörigkeit
von Athleten ist jedoch interessant für eine spätere empirische Klassifizierung
von Sportarten. So kann z.B. festgestellt werden, welche Durchschnittswerte
eines medizinischen Messwertes für eine gewisse Sportart typisch ist.
Hier spielen die
Möglichkeiten der Klassifikation eine Rolle, die als Entscheidungshilfe für
Athleten dienen kann. Ein junger Sportler kann nun überprüfen, für welche
Sportart er aufgrund der Ergebnisse seiner Leistungstests, seiner Statur und
prüfbaren Anlagen geeignet ist.
Auf der anderen
Seite kann ausgewertet werden, welche Sportarten „kompatibel“ sind, d.h. die
gleichen Voraussetzungen aufweisen. Dies kann dazu dienen, gegenseitigen
Erfahrungsaustausch unter diesen Sportarten zu forcieren oder direkt auf
generiertes Wissen anderer Sportarten zurückzugreifen.
10 Benutzerschnittstellen
Da das System vorwiegend von zwei Benutzergruppen verwendet wird, wurden zwei verschiedene Zugangsformen implementiert. Die Benutzergruppen sind einerseits Trainer, welche Trainingspläne erstellen und Auswertungen der Daten vornehmen und andererseits die Athleten, welche Trainingspläne als Vorgaben verwenden und Dokumentationsdaten festhalten. Die Trainerversion erlaubt vollen Zugang und Verwaltung der Datenbank, während für Athleten ein „thin Client“ sowohl als Desktop- als auch als Internetapplikation mit geringem Funktionsumfang implementiert wurde.
10.1
Zentralapplikation
Verwaltungssoftware für die Datenbank wurde in C++ implementiert. Ziel war es, eine benutzerfreundliche Oberfläche zu entwickeln, die dem Trainer die Arbeit bei der Trainingsplanung und Analyse erleichtert.
Verwaltungsaufgaben, wie die Personenverwaltung und das Einrichten von Basisdaten erfolgen hier, bevor die Datenbank den anderen Benutzern zugänglich gemacht wird.
Auf dieser Plattform werden auch Datenanalysen und Prognosen durchgeführt.
Die in diesem Zugangsweg zur Datenbank implementierten Funktionen erfordern ein gewisses Maß an Verständnis für Datenbanken und den Aufbau des grundlegenden Systems der Trainingsdatenerhebung.
10.1.1 Installation
10.1.1.1 Datenbank
Das Anlegen einer neuen Datenbank besteht grundsätzlich nur darin, eine neue Datei zu erstellen, da ein Desktop-Datenbanksystem zum Einsatz kommt.
Alternativ zum erstellen einer leeren Datenbank kann eine mitgelieferte Standarddatenbank kopiert und weiter angepasst werden. Die Anpassung und Konfiguration der Datenbank erfordert etwas höheren Aufwand.
10.1.1.2 Konfiguration
Zur Konfiguration des Systems ist es nötig, Grundlegendes über den Aufbau des zu Grunde liegenden Datenbanksystems zu wissen. Daher wird dieser Punkt gesondert angesprochen. Speziell für das hierarchische System der Messwerte muss der Benutzer wissen, wie diese Daten zusammenhängen und wo sie später im System angewandt werden.
Im Weiteren ist der Anpassung der Trainingsmethoden besonderes Augenmerk zu widmen. Bei der Definition einer neuen Trainingsmethode (Kategorie) werden zwei Tabellen für die kategoriespezifischen Parameter angelegt, für Planung und Dokumentation.
Folgende Vorgehensweise ist nötig (für Details siehe 9.2.3):
- Definition der Basismesswerte mit den zugehörigen Messeinheiten.
- Definition der spezifischen Messwerte, basierend auf den Basismesswerten.
- Definition der Intensitätsbereiche und Zuweisung von spezifischen Parametern zur Bestimmung dieses Bereichs.
- Definition der Trainingskategorien und Zuweisung von kategoriespezifischen Parametern (diese können nicht mehr geändert werden).
10.1.1.3 Sonstige Daten eingeben
Als sonstige Daten sind vor allem Personen, Sportarten und Teams zu sehen. Die Definition von Athleten ist Grundvoraussetzung für die Arbeit mit dem System, da die meisten Daten spezifisch für jeden Athleten abgelegt werden.
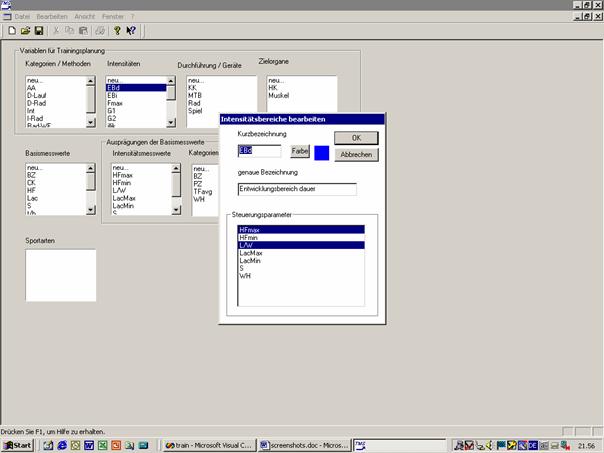
Abbildung 15 Bearbeiten der Grundeinstellungen mit offenem Dialog für Intensitätsbereich
10.1.2 Implementierung
Die Zentralapplikation wurde in Visual C++ 6.0 entwickelt unter Verwendung der MFC-Klassenbibliothek.
Aufgrund des großen Umfanges wird auf einen Anschluss des Quellcodes verzichtet. Im Folgenden wird die Vorgehensweise bei der Implementierung kurz beschrieben.
10.1.2.1 Ansicht/Dokument-Struktur
In der Dokumentenklasse (abgeleitet von CDocument) wird die Datenlogik gehalten. Das Dokument enthält Informationen zur Datenauswahl und Datenfilterung. Die Daten selbst werden hier nicht direkt gespeichert, sondern der Zugriff erfolgt über einen Zeiger zur Datenbankzugriffklasse (siehe 10.1.2.2). Somit ist die Anwendungslogik in dieser Klasse gekapselt.
Die Ablauflogik wird von Ansichts- und Rahmenklassen (abgeleitet von CView bzw. CMDIChildFrame) gesteuert. Die Ansichtsklasse stellt die Daten des zugehörigen Dokuments dar. Alle Benutzereingaben werden von der Ansichtsklasse entgegengenommen und soweit Datenmanipulationen erfolgen an die Dokumentenklasse weitergeleitet.
Die Rahmenklasse ist für das Aussehen des Fensters verantwortlich.
10.1.2.2 Datenbankzugriffsklassen
Datenbankzugriffe werden durch Klassen für die einzelnen Tabellen gekapselt. Als Basisklasse wird CDaoRecordset verwendet.
In diesen Recordset-Klassen (CRSx) wird auch die Integrität der Datenbank gewährleistet. Bei der Veränderung von Daten in einzelnen Tabellen werden Abhängigkeiten festgestellt und andere Tabellen nachgezogen.
10.1.2.3 Klassenübersicht
In der folgenden Tabelle werden die wichtigsten implementierten Klassen angeführt.
Auf die Angabe von einfachen Dialogklassen wird verzichtet.
|
Klassenname |
Basisklasse |
Funktion |
|
Allgemeine Klassen des MFC-Gerüst |
||
|
CTrainApp |
CWinApp |
zentrale Windows-Applikation |
|
CMainFrame |
CMDIChildWnd |
|
|
CTrainDoc |
CDocument |
Dieses zentrale Dokument repräsentiert eine Datenbank-Datei. Es enthält einen Zeiger auf das CDaoDatabase-Objekt. Von hier aus erfolgt auch die Verwaltung der übrigen Datenzugriffsdokumente. |
|
CTrainTreeView |
CTreeView |
Die Ansichtsklasse des zentralen Dokuments CTrainDoc. |
|
DOKUMENT- UND ANSICHTSKLASSEN der Verwaltung |
||
|
CAthletListDoc |
CDocument |
Dokument zur Bearbeitung der verwalteten Athleten. |
|
CAthletListView |
CListView |
Ansichtsklasse für CAthletListDoc |
|
CAthletDataDoc |
CDocument |
Dokument zur Bearbeitung der Stammdaten eines Athleten. |
|
CAthletDataForm |
CFormView |
Ansichtsklasse (Formular) für CAthletDoc. |
|
CBasicDataDoc |
CDocument |
Dokument zur Bearbeitung der Basisdaten. (Trainingsbereiche, Messdaten,...) |
|
CBasicDataFormView |
CFormView |
Ansichtsklasse für BasicDataDoc. |
|
CHtmlHelpDoc |
CDocument |
Html-Dokument für die Anwender-Hilfe |
|
CHtmlHelp |
CHtmlView |
Ansichtsklasse für CHtmlHelpDoc |
|
CParameterDoc |
CDocument |
Dokument zur Bearbeitung der Intensitätsparameter (Trainingsbereiche) eines Athleten. |
|
CParameterForm |
CFormView |
Ansichtsklasse für CParameterDoc. |
|
CMedDataDoc |
|
Dokument zur Bearbeitung der medizinischen Messwerte eines Athleten. |
|
CMedDataForm |
|
Ansichtsklasse für CMedDataDoc. |
|
DOKUMENT- UND ANSICHTSKLASSEN des Planungsprozesses |
||
|
CDiaryDoc |
|
Basisdokument für Tagebücher. |
|
CDiaryView |
|
Anasichtsklasse für Tagebücher. |
|
CPlanDoc |
|
Dokument für Trainingsplan |
|
CPlanChartView |
|
Chart-Ansicht für Trainingsplan |
|
CPlanGridFormView |
|
Tabellen-Ansicht für Trainingsplan |
|
CPlanSessionDlg |
|
Dialog für die Bearbeitung einer Trainingseinheit. |
|
CAnalyseDoc |
|
Dokument für Analyse. |
|
CAnalyseView |
|
Ansichtsklasse für Analyse. |
|
CPeriodPlanDoc |
|
Dokument für die Periodenhierarchie. |
|
CPeriodPlanView |
|
Ansichtsklasse für CPeriodPlanDoc |
|
|
|
|
|
CNeuronalNet |
|
Klasse hält ein neuronales Netz |
|
CStatistic |
|
Klasse hält eine Statistik-Tabelle |
|
CStatisticTableDoc |
|
Dokument zum Bearbeiten einer Statistik-Tabelle. |
|
CStatisticTableView |
|
Ansichtsklasse für CStatisticTableDoc. |
|
CStatTable |
|
Klasse repräsentiert die Tabelle. |
|
DATENBANK-ZUGRIFFSKLASSEN |
||
|
CRSIniData |
|
Persönliche Einstellungen des Users. Vorwiegend Farben, Anzeigeoptionen, Anzeigewertebereiche, usw. |
|
CIniData |
- |
Zugriffsklasse für CRSIniData |
|
CRSAthlet |
CDaoRecordset |
Stammdaten des Athleten. |
|
CRSCategoryDef |
|
Definition der Trainingskategorien. |
|
CRSCatMeasureDef |
|
Messeinheiten für die Trainingskategorien. |
|
CRSCatParData |
|
Trainingskategoriedaten für eine Trainingseinheit. |
|
CRSCatParDef |
|
Definition der Trainingskategorieparameter |
|
CRSDeviceDef |
|
Definition der Trainingsmittel. |
|
CRSIntensityDef |
|
Definition der Trainingsbereiche. |
|
CRSIntMeasureDef |
|
Messeinheiten für die Trainingsbereiche. |
|
CRSIntParDef |
|
Definition der Trainingsbereichsparameter. |
|
CRSMeasureDef |
|
Definition der Basismesswerte. |
|
CRSMedData |
|
Medizinische Messdaten eines Athleten. |
|
CRSMedMeasureDef |
|
Messeinheiten für Medizinische Messdaten. |
|
CRSParData |
|
Trainingsbereichsdaten eines Athleten. |
|
CRSPeriodData |
|
Trainingsdaten für eine Periode. |
|
CRSPeriodPlan |
|
Hierarchie für die Periodeneinteilung. |
|
CRSSessionData |
|
Daten einer Trainingseinheit. |
|
CRSSportDef |
|
Definition der Sportarten. |
|
CRSTargetDef |
|
Definition der Trainingsziele. |
|
CRStdSessionName |
|
Name von Vorlagen für Standardtrainingseinheiten. |
|
CRSvCatParData |
- |
Zugriffsklasse für kategoriespezifische Parameter einer Trainingseinheit. |
Tabelle 8 Klassenübersicht der Implementierung in C++/MFC
10.2
Web-Inferface
Um möglichst vielen Athleten die Möglichkeit zu geben, das System zu nutzen und nicht zu letzt um eine breite Datenbasis zu erlagen, ist die Einrichtung eines Web-Interfaces für die Datenbank vorgesehen.
Die Voraussetzung ist natürlich ein Internetzugang aller beteiligten Personen, was jedoch bei der Einführung des Systems am Beginn des 21. Jahrhunderts keinen Engpass mehr darstellt.
Die Funktionen der Intenet-Applikation beschränken sich auf das Abrufen von Trainingsplänen und die Dokumentation von Trainings- und Kontrolldaten.
10.2.1 Anforderungen
Das Web-Interface wird von Laien bedient, die nur generelles Verständnis für EDV haben, aber kaum für Datenbanken oder auch nur für das vom Trainer selbst aufgesetzte System von Variablen und Messwerten zur Bestimmung der Parameter.
Aus diesem Grund ist besonderer Wert auf eine einfache und selbstsprechende Darstellung zu legen, die von einem Sportler instinktiv bedient werden kann.
10.2.2 Design
Als Design bietet sich aufgrund der in den Anforderungen angeführten Faktoren ein möglichst einfaches Formular an, in das alle Daten des jeweiligen Tages eingetragen werden können. Die meisten Athleten sind mit Datenblättern, Trainingstagebüchern oder ähnlichen Protokollen vertraut, sodass eine Anlehnung an diese bekannten Formen sinnvoll erscheint.
10.2.3 Implementierung
Die Web-Applikation wurde mit Hilfe von Java Server Pages realisiert. Mittels ODBC-Treiber kann auf die Datenbank zugegriffen werden.
11 Module des
Systems
11.1
Trainingsplanung
In der Phase der Trainingsplanung ist es die Aufgabe des Trainers, Vorschläge und Handlungsanweisungen für eine vorgegebene Periode zu geben.
Wie in 3.4 beschrieben, läuft der Trainingsplanungsprozess meist in einer hierarchischen Struktur ab.
In der folgenden Abbildung ist dieser Prozess nochmals anschaulich dargestellt.
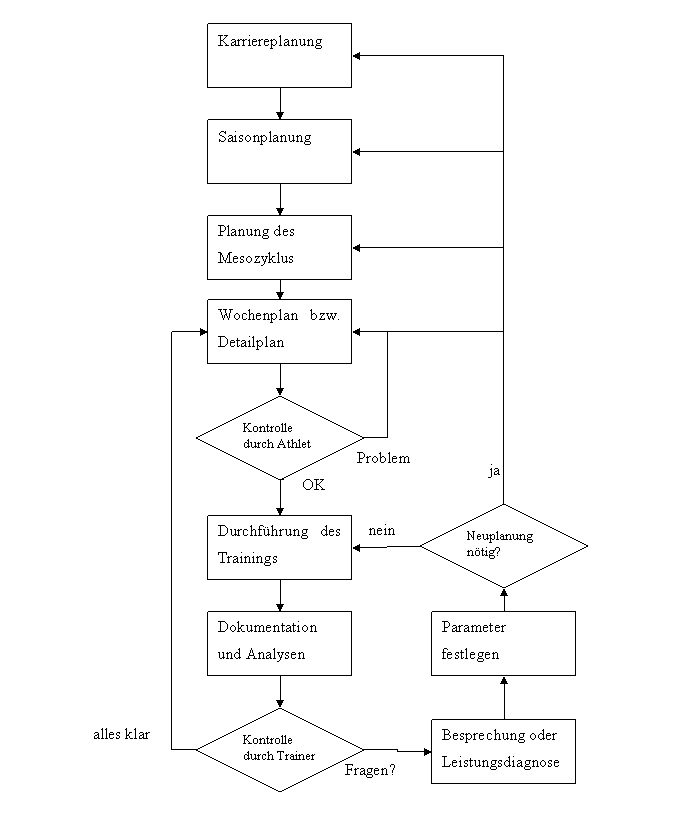
Abbildung 16 Typischer Ablauf des Trainingsplanungsprozesses
11.1.1 Periodisierung
11.1.1.1 Perioden-Plan
Im Periodenplan wird die gesamte Karriere eines Athleten in Perioden eingeteilt. Üblicherweise wird mit Jahren begonnen. Die Jahre werden in Trainingsphasen geteilt (Aufbau, Wettkampf, Regeneration, etc.). Die Phasen bestehen wiederum aus Mesozyklen, die sich aus Wochen zusammensetzten.
Dieser Standardplan soll jedoch den Trainer nicht dazu nötigen, an externe Vorgaben wie Monate, Wochen etc. anzuknüpfen. Durch die eigenständige Definition von Perioden hat er die Möglichkeit, die Perioden so zu wählen, wie es dem Trainingsaufbau optimal entspricht.
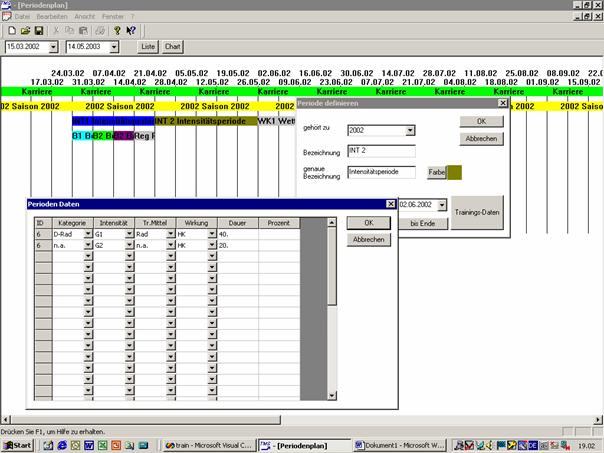
Abbildung 17 Periodenplanung – Hierarchie und Dialog mit Periodendaten
11.1.1.2 Perioden-Daten
Nachdem die Perioden zeitlich festgelegt wurden, müssen sie mit Inhalten gefüllt werden.
Die inhaltliche Definition einer Periode erfolgt nach der Trainingszeit in einer bestimmten Trainingscharakteristik. Somit kann jedem beliebigen Tuppel (Kategorie, Intensität, Trainingsmitte, Trainingsziel) der entsprechende Trainingsumfang zugewiesen werden. Auch hier ist ein hierarchischer Aufbau vorgesehen. Indem einzelne der vier Variablen undefiniert gelassen, bzw. als „don’t care“ markiert werden, kann die Summe der untergeordneten Tuppel definiert werden.
Dies soll an folgendem Beispiel verdeutlicht werden: Es sollen in einer Periode 20 Stunden Training im „Intensitätsbereich G1“, nach der „Dauermethode“ mit dem Ziel der Entwicklung des „Herz-Kreislaufsystems“ durchgeführt werden. Das Trainingsmittel spielt dabei vorerst keine Rolle. In einer weiteren Detaillierung wird vorgegeben, dass davon 15 Stunden mit dem „Rennrad“ durchgeführt werden sollen und 5 Stunden als „Lauftraining“.
Ausgegangen wird dann üblicherweise von einem vollständigen „don’t care“-Tuppel, welches keine Rücksicht auf die einzelnen Charakteristika nimmt, sondern nur die Gesamtzeit der Periode festlegt.
Bei der vorliegenden Methode ist dem Trainer jedoch freigestellt, ob er einen Top-Down-Ansatz wählt, wie oben beschrieben, oder einen Bottom-Up-Ansatz. Das heißt, er definiert zuerst die Trainingseinheiten und lässt sich dann die Gesamtbelastungen errechnen. Daraus ergeben sich 16 Kombinationen pro Endkombination, von denen sinnlose und doppelte Tuppel gelöscht werden können. Speziell die Gesamtzeit muss in jedem Rechengang das gleiche Ergebnis liefern.
Es können auch Ebenen übersprungen werden, indem von zwei „don’t care“-Positionen direkt konkrete Inhalte abgeleitet werden.
Wird der Eintrag einer Periode geändert, so müssen alle Einträge dieser Periode, sowie der hierarchisch vor- und nachgelagerten aktualisiert werden. Dies soll am folgenden Beispiel verdeutlicht werden: Einem Mesozyklus sind vier Wochen zugeordnet. Der gesamte Mesozyklus soll 80 Stunden umfassen, die vier Wochen jeweils 20 Stunden. Wird in einer Woche der Plan auf 25 Stunden erhöht, so gibt es zwei Möglichkeiten. Entweder es verändern sich die Werte der anderen drei Wochen oder es verändert sich die Gesamtzeit des Mesozyklus.
11.1.2 Detailplanung
Wurde nun beschlossen, welche Belastungssummen in den einzelnen Perioden beinhaltet sein sollen, müssen diese Vorgaben in konkreten Handlungsanweisungen konkretisiert werden. Es wird laufend angezeigt, welche Umfänge der verschiedenen Kategorien noch zu verteilen sind.
![]()
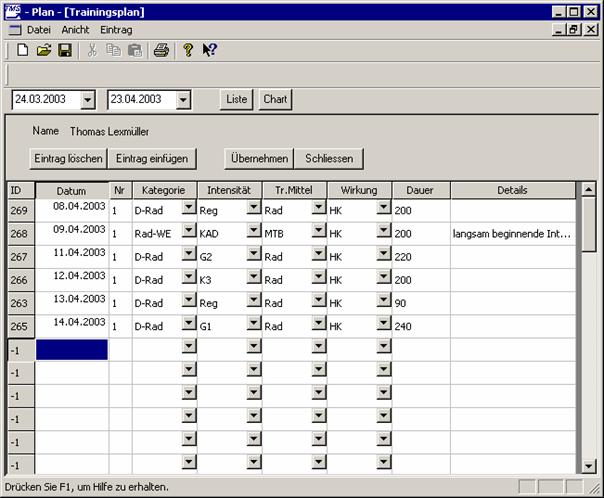
Abbildung 18 Detailplanung in der Tabellenansicht
![]()
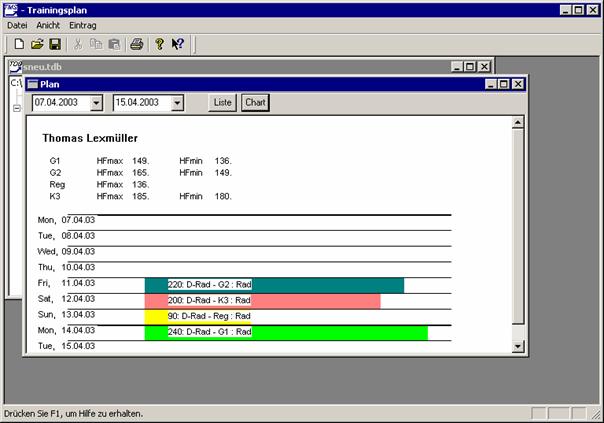
Abbildung 19 Detailplanung in der Chartansicht
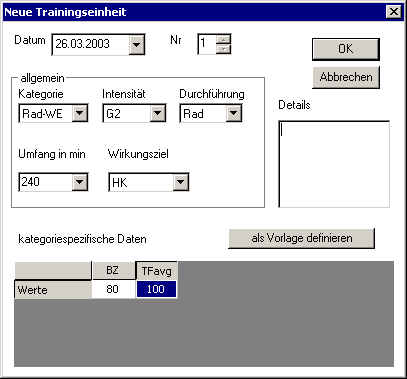
Abbildung 20 Dialog zum Einfügen oder Bearbeiten einer Trainingseinheit
11.1.2.1 Vorlagen
Da immer wiederkehrende Trainingseinheiten eingesetzt werden, kann der Aufwand bedeutend reduziert werden, indem Vorlagen definiert werden.
Die Definition von Standardeinheiten erfolgt aus praktischen Gründen direkt beim Einfügen von Trainingseinheiten.
Die Vorlagen werden in die gleiche Tabelle eingetragen wie die Trainingseinheiten des Plans.
Zusätzlich kann ihnen ein sprechender Name gegeben werden, der in einer eigenen Tabelle gespeichert wird.
Wenn die Datenbank von sehr vielen Trainern verwendet wird, ist auch zu überlegen, ob die Vorlagen einem oder mehreren Trainern zugeordnet werden sollen. Dadurch könnte vermieden werden, dass zu viele Vorlagen zu einer unübersichtlichen Oberfläche führen.
Dadurch wäre auch zu vermeiden, dass konkurrierende Trainer Zugriff auf die Daten des anderen haben.
11.1.3 Datenübertragung
Zur Übermittlung des Plans an den Athleten stehen mehrere Medien zur Verfügung.
- Ausdruck – der Plan wird auf Papier ausgedruckt und dem Athleten übergeben oder per Fax übermittelt.
- Email einer Datenaustauschdatei – es besteht die Möglichkeit den Plan als Trainingsdaten-Austauschdatei (.tdx) zu exportieren und direkt über email zu versenden. Diese Datei kann vom Athleten in seiner lokalen Datenbank importiert werden.
- Email einer Text-Tabelle – die Daten des Plans können auch in eine Text-Tabelle exportiert werden. In dieses Format sind die Spaten tabulatorgetrennt wodurch die Tabelle in konventionelle Tabellenkalkulationsprogrammen weiterverarbeitet werden kann.
11.2
Dokumentation
11.2.1 Trainingsdaten
Der Athlet dokumentiert das durchgeführte Training in der gleichen Form wie der Trainingsplan. Auf diese Weise sind in weiterer Folge Analysen und Vergleiche möglich.
Sollen Informationen festgehalten werden, die nicht strukturierbar sind, so besteht die Möglichkeit, diese in Textform festzuhalten.
11.2.2 Medizinische Messdaten
Unter diesem Begriff werden der Einfachheit halber alle Kontroll-Messdaten zusammengefasst, die regelmäßig oder in unregelmäßigen Abständen personenspezifisch aufgenommen werden. Die Aufnahme der Daten kann sowohl durch den Trainer, Arzt oder Athleten selbst erfolgen. (siehe 4.3).
Die vom Athleten mitprotokollierten Daten können entweder direkt über das Web-Interface an die Datenbank übertragen werden oder auch vom Trainer gesammelt eingegeben werden.
Werden die Daten über das Web eingegeben, so ist es wichtig, eine Plausibilitätskontrolle der Daten vorzunehmen. Sowohl Übertragungsfehler, als auch Eingabefehler sollten in gewissem Maße erkannt werden. Dazu wird zumindest jedem Wert ein Gültigkeitsbereich zugeordnet.
![]()
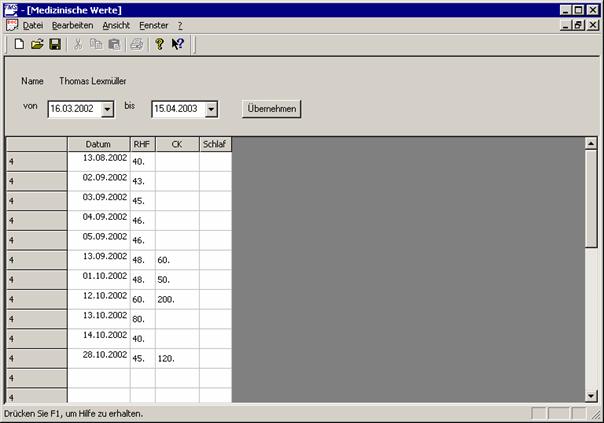
Abbildung 21 Dokument zum Eintragen „medizinischer Messwerte“
11.3
Analysen
11.3.1 Einfache Analysen
Die einfachste Form der Analyse ist eine Gegenüberstellung von Planung, Durchführung und Kontrollwerten. Die Daten werden hier noch nicht weiter aufbereitet oder berechnet.
Ziel ist lediglich eine Visualisierung der Daten, um diese für den menschlichen Beobachter verwertbar zu machen.
Welche Kontrolldaten und welche Trainingsausprägungsformen angezeigt werden sollen, kann in einem Dialog definiert werden.
Für die Kontrollwerte können Anzeigebereiche gewählt werden. Die „Ruheherzfrequenz“ ist bspw. nur innerhalb des Wertebereichs 30 bis 70 relevant.
Durch die visuelle Aufbereitung und Gegenüberstellung von Training, Umgebungsvariablen und medizinischen Kontrollwerten kann der menschliche Beobachter zusammenhänge intuitiv erkennen.
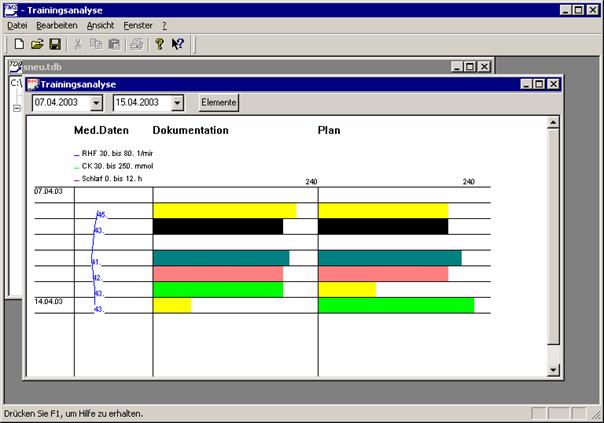
Abbildung 22 Visualisierung von Plan- und Dokumentationsdaten für die Analyse
11.3.2 Soll-Ist-Vergleich
Diese Analysemethode besteht darin, geplantes Training mit tatsächlich durchgeführtem Training zu vergleichen. Der Vergleich kann sich sowohl auf einzelne Trainingseinheiten beziehen, als auch auf zuvor definierte Perioden.
11.3.2.1 Detailvergleich
Die Anzeige erfolgt durch die Anzeige von Differenzwerten. Üblicherweise wird die Anzeige der Differenzwerte mit der Anzeige der Dokumentationsdaten kombiniert. So kann auch besser abgeschätzt werden, wie wesentlich die Abweichungen im Vergleich zum durchgeführten Training sind.
Es sind dabei folgende Fälle möglich.
- Gleiches Training mit gleichem Umfang:
Es wird ein „ok“-Zeichen eingetragen.
- Gleiches Training mit unterschiedlichem Umfang:
In diesem Fall wird die Differenz als positive oder negative Ausprägung von einer Null-Achse dargestellt. Ist der Wert positiv, so wurde das Training in höherem Umfang durchgeführt, ist er negativ, so wurde der vorgegebene Umfang nicht erreicht.
- Alternatives Training:
Wird nicht das geplante Training durchgeführt, sondern eine andere Ausprägung gewählt, so wird das durchgeführte Training positiv eingezeichnet und das geplante, nicht durchgeführte negativ. Um die Anzeige übersichtlicher zu gestalten, hat der Trainer die Möglichkeit beliebige Variablen als „don’t care“ zu markieren.
So ist es bspw. egal, ob „Grundlagentraining“ mit dem „Rennrad“ oder dem „Mountainbike“ durchgeführt wird. Der Trainer stellt die entsprechende Variable so ein, dass sie nicht für die Unterscheidung herangezogen wird.
Wenn eine genauere Differenzierung nötig ist, könnte eine Äquivalenztabelle eingeführt werden. Dort wird z.B. eingetragen, dass „Mountainbike“ und „Rennrad“ äquivalent verwendet werden können, nicht aber andere Trainingsmittel wie z.B. „Laufen“.
Ein häufig auftretender Spezialfall ist eine Verschiebung des Trainings um einen Tag. In der normalen Grafik werden dann ein positiver und ein negativer Eintrag hintereinander dargestellt. Um die Darstellung zu bereinigen, können diese Einträge gegeneinander kompensiert werden, indem ein Eintrag mit der Maus auf den anderen geschoben wird.
Auf diese Weise bleiben nur die tatsächlich wirksamen Unterschiede über und der Trainer kann sich darauf konzentrieren, diese zu beurteilen.
Wenn eine Umdisponierung des Trainings erfolgt, ist es wichtig anzugeben, welche Gründe dafür ausschlaggebend waren. Die Begründung wird verbal formuliert und in den „Details“ der Trainingsdokumentation aufgezeichnet.


![]()
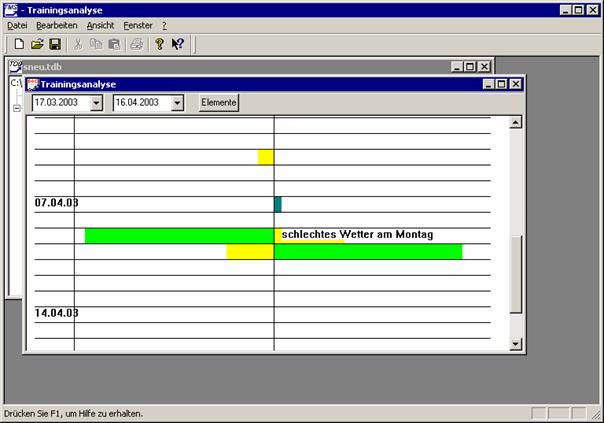
Abbildung 23 Soll-Ist-Vergleich mit Verschiebung zweier Einheiten und Begründung
Alternativ dazu könnte auch die Angabe von Gründen standardisiert werden. Für jede Abweichung wird ein Eintrag in eine „Begründungstabelle“ eingetragen, mit folgendem Aussehen (TrainingseinheitID, AbweichungID, Text).
Die Begründung wird automatisch verlangt, wenn der Athlet einen Eintrag vornimmt, der vom Plan über ein bestimmtes Niveau abweicht.
11.3.2.2 Periodenvergleich
Für den Vergleich von Perioden werden die Belastungssummen der einzelnen Trainingsausprägungsformen herangezogen.
Als Plan kann entweder der Periodenplan herangezogen werden, oder die Summe aus den resultierenden Einzeltrainingseinheiten. Da zwischen den beiden Plänen Diskrepanzen auftreten können, empfiehlt sich die Berechnung aus der Detailplanung, da diese auch dem Athleten als Vorgabe dient.
Der häufigste Fall wird sein, dass einige Variablen außer Kraft gesetzt werden und der Vergleich z.B. nur nach den Intensitätsbereichen erfolgt.
Im Zusammenhang mit der Periodenanalyse ist folgende Überlegung anzustellen, die im vorliegenden System noch nicht implementiert wurde. Im Zuge von kurzfristigen Anpassungen des Trainings kann es zur Verschiebung einer durchgeführten Einheit in eine andere Planungsperiode kommen.
Dieses Problem ist aus der betriebswirtschaftlichen Erfolgsrechnung und dem Controlling bekannt, wenn Rechnungsperioden und Produktionsperioden auseinanderfallen.
Für die Lösung dieses Problems sind verschiedene Möglichkeiten denkbar. Wenn die Länge einer Periode keinen konkreten Analysewert besitzt, so können zwei Periodenhierarchien gehalten werden, eine für die Planung und eine für die Dokumentation bzw. Analyse. Diese Vorgehensweise führt dazu, dass Perioden nicht mehr absolut vergleichbar sind. Eine Trainings-„Woche“ kann dann sechs, die andere acht Tage haben. Dadurch ist auch ein zeitraumbezogener Indikator (z.B. durchschnittliche Trainingszeit pro Tag) nur schwer zu interpretieren.
Die andere technische Möglichkeit ist, eine Liste mit Zuweisungskorrekturen zu führen. Jede Trainingseinheit, die nicht der Periode zugewiesen werden soll, in die ihr Datum fällt wird in eine Liste eingetragen und mit Verweis auf die gewünschte Periode versehen.
Die Methoden des Periodenabgleichs müssen in jedem Fall eng mit dem Trainer abgestimmt werden, damit dieser die Ergebnisse richtig interpretieren kann.
12 Datenanalyse
und Modellbildung
Die gesammelten Daten sollen auch in ihrer Bedeutung untersucht werden und entsprechend gruppiert und eingeordnet werden. Auf den so aufbereiteten Daten können dann Analysen durchgeführt werden. Zusätzlich sind Methoden zur Bildung von Modellen implementiert, die in weiterer Folge für Prognose und Simulation dienen werden.
12.1
Vorbereitungen
Um eine Auswertung vornehmen zu können, müssen diese Rohdaten in eine entsprechende Form gebracht werden. Die Aufbereitung der Daten wurde an die Form von Eingabetabellen für Standard-Statistik-Programme angelehnt. Auf diese Weise ist es relativ leicht möglich, die Daten zu exportieren und in einem dieser Standardprogramme zu analysieren.
Die Auswahl der Variablen, welche als Basis für die weitere Bearbeitung verwendet werden sollen, ist der erste Schritt für jede Form der Analyse.
Da es sich bei allen Daten um Zeitreihen handelt, müssen diese in eine entsprechende Form gebracht werden, um sie späteren Analysen zuführen zu können.
12.1.1 Datenauswahl
In einem Dialog werden die Daten gewählt, die für die Analyse herangezogen werden sollen. Auszuwählen sind:
- Athleten
- gesamte Trainingskategorie oder einzelne Parameter einer Kategorie
- Medizinische Messwerte
- Zeitbereich
Jeder dieser ausgewählten Variablen wird eine Spalte in der Statistiktabelle zugewiesen.
12.1.2 Statistiktabelle
Als Statistiktabelle wird im Folgenden eine Tabelle bezeichnet, die Daten in geeigneter Form aufnehmen kann, um sie später mit Analysemethoden zu verarbeiten.
Zunächst ist es die Aufgabe, die ausgewählten Daten aus den verteilten Tabellen in eine einzige zu vereinen. Dabei sind sie in chronologischer Reihenfolge zu ordnen und nach ihrer Zugehörigkeit zu Athleten zu trennen.
Für die Zuordnung zu Datensätzen wurde eine Diskretisierung in Kalendertage gewählt. Meist ist nur ein Datensatz (medizinische Werte und Trainingseinheiten) pro Tag aufgezeichnet.
Bei Trainingseinheiten kann es vorkommen, dass mehrere an einem Tag durchgeführt werden.
In diesem Fall wird ein zusätzlicher Datenpunkt mit dem gleichen Datum eingefügt. Die Behandlung dieses Falles bei der Analyse verbleibt im Verantwortungsbereich der Datenaufbereitung bzw. der Analyseverfahren selbst.
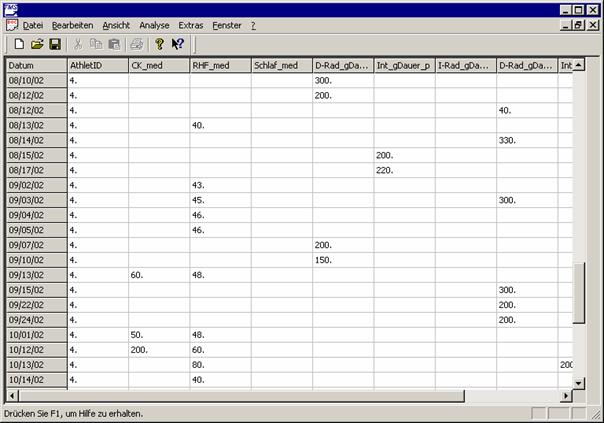
Abbildung 24 Statistiktabelle, generiert aus der Datenbank
12.2
Statistik
Die Auswertung mit konventionellen statistischen Methoden ist nur unter bestimmten Prämissen und Anforderungen möglich, die an den Datenbestand gestellt werden.
So können durchaus Hypothesen formuliert und überprüft werden, es ist jedoch nicht oder nur mit hohem Aufwand möglich komplexe Zusammenhänge zwischen den Variablen aufzufinden (siehe 7.2.2).
Die statistische Auswertung ist aus dem Programm ausgelagert, da Standardpakete umfangreiche Funktionalität zur Verfügung stellen.
Ein weiterer Vorteil der Auswertung in einem anderen Programm ist eher psychologischer Art. Es ist darauf zu achten, dass statistische Analysen nicht vorbehaltlos ausgeführt und bewertet werden. Die Auswertung sollte zumindest zu Beginn jemand begleiten, der mit statistischen Methoden vertraut ist und auch Grenzen der Interpretierbarkeit der Ergebnisse kennt.
Aufgrund der großen Zahl der am Markt vorhandenen Produkte zur statistischen Auswertung wurde auf eine Implementierung im System selbst verzichtet. In späteren eventuell kommerziellen Versionen könnten Bibliotheken von Statistikprogrammen direkt im System integriert werden um eine erhöhte Benutzerfreundlichkeit zu gewährleisten.
12.3
Analyse- und Modellbildungsverfahren
In der Implementierung werden einige Verfahren zur Verfügung gestellt, um die Konstruktion eines Simulationsmodells zu ermöglichen.
12.3.1 Neuronales Netz
Ausgangsbasis für
den Einsatz eines neuronales Netzes zur Datenanalyse ist die Erstellung einer
Statistiktabelle (siehe 12.1.2). Von dort aus, ist über den Menüpunkt „Analyse –
Neuronales Netz“ der Dialog zur Konfiguration des neuronalen Netzes zu
erreichen.
In diesem Dialog
scheinen alle Variablen der Statistiktabelle auf. Nun wird die Struktur des
Modells festgelegt, welches durch das neuronale Netz berechnet werden soll.
Die Variablen aus
der Statistiktabelle werden einer der folgenden Kategorien zugewiesen.
- Eingangsvariablen
- Ausgangsvariablen
- Zustandsvariablen (Ein-/Ausgang)
Graphisch
dargestellt sieht die Topographie des Netzes wie folgt aus:
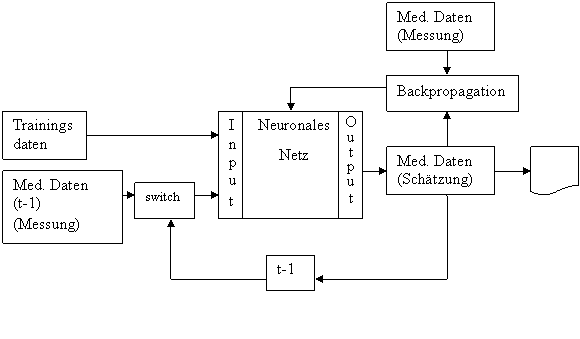
Abbildung 25 Gesamtstruktur des
Modells mit neuronalem Netz
„switch“ ist eine Alternativauswahl. Sie wird verwendet für Zustandsvariable, die
in jeder Berechnungsphase im Netz anliegen müssen.
Liegt ein Signal
am Eingang vor, d.h. ist eine Variable in der Eingangstabelle eingetragen, so
wird dieses gewählt. Ist für dieses Berechnungsschritt keine gemessene Variable
vorhanden, so wird diese vom Netz geschätzt und direkt als Eingangsvariable
übernommen. Als Schätzwert wird der Ausgang des Neuronalen Netzes des
vorhergehenden Rechenschrittes herangezogen.
„t-1“ repräsentiert eine Verzögerung um eine Periode. Der geschätzte Zustand
einer Periode dient als Ausgangszustand der nächsten Periode, sofern die Daten
nicht durch eine tatsächliche Messung korrigiert werden.
Als Ergebnis der
Analyse wird in jedem Moment der Zustand des Athleten über medizinische
Messparameter dargestellt. Auf diese Weise kann überprüft werden, welchen
Zustand der Athlet nach simuliertem Training im Modell erreicht. Im Speziellen
wird geprüft ob Kontrollwerte den Normbereich verlassen und ob die
Leistungsfähigkeit wie geplant zunimmt.
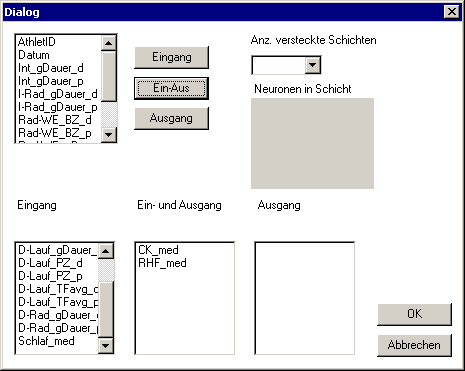
Abbildung 26 Dialog zur Auswahl der Ein- und Ausgangsgrößen des neuronalen Netzwerks
13 Chancen und
Grenzen der Informatik
Als abschließende Zusammenfassung der vorhergehenden Überlegungen sollen nochmals konkrete Ansatzpunkte herausgestrichen werden, in denen Einsatzmöglichkeiten der Informatik liegen.
Neben der Vereinfachung und Standardisierung der Planungsarbeit ist vor allem die Datenerhebung und die Überwachung der Kontrollparameter eine konkrete Einsatzmöglichkeit von Informatiksystemen.
Gleichzeitig werden auch Grenzen aufgezeigt, welche nach derzeitigem Stand der Technik als nicht realisierbar erscheinen.
13.1
Prozessunterstützung
Eine der Hauptaufgaben könnte der Informatik in der Ablaufunterstützung im Trainingsmanagementprozess zukommen.
In den Bereichen in denen eine Erleichterung der Arbeit des Trainers erreicht werden kann, ohne ihn in seiner Handlungsfreiheit zu beschränken kann mit einer großen Akzeptanz gerechnet werden.
13.2
Modell und Realität
Eine klare Grenze an welche jede Form der Modellbildung stößt ist die Tatsache, dass eine Abbildung der Realität in ein Modell meist mit Verlust von Informationen verbunden ist. Bei sehr komplexen Systemen ist die Frage zu klären, ob eine hinreichend genaue Abbildung grundsätzlich erreicht werden kann.
Speziell bei automatischer Modellbildung aus empirischen Daten (z.B. neuronale Netze siehe 7.6) muss abgeschätzt werden, wieweit die Gültigkeit der Übertragungsfunktion außerhalb der verwendeten Daten gültig ist.
13.3 Automatische
Planerstellung
Planung und Optimierung sind die höchsten Stufen von Expertensystemen (siehe 5.2). Aus technisch, theoretischer Sicht stößt daher die völlig Automatische Erstellung von Trainingsplänen an Grenzen. Speziell im Spritzensport, wo im Grenzbereich trainiert wird und großer Wert auf die Optimierung gelegt wird, scheint der Einsatz unmöglich. Dies trifft nicht unbedingt auf den Breitensport zu. Dort ist die Optimierung nur eingeschränkt nötig und es kann von einer größeren Standardisierung ausgegangen werden.
Ein Punkt, der bei der Planerstellung eine große Rolle spielt, ist die Intuition des Trainers. Erfahrung und das „Kennen“ des Athleten sind Informationen, die nur sehr schwer technisch gespeichert oder generiert werden können.